
Learning Steerable Clarification Policies with Collaborative Self-play
To handle underspecified or ambiguous queries, AI assistants need a policy for managing their uncertainty to determine (a) when to guess the user intent and answer directly, (b) when to enumerate and ...
More generally, training models to respect scalar values that specify a reward in the prompt is useful!
There are more results in the paper, check it out...
arxiv.org/abs/2512.04068
With Max Chen, Adam Fisch, Reza Aghajani, Mirella Lapata,
@jacobeisenstein.bsky.social, @fantinehuot.bsky.social
06.03.2026 00:24
👍 0
🔁 0
💬 0
📌 0

Models also generalize to coefficients that never occurred at training time!
06.03.2026 00:24
👍 0
🔁 0
💬 1
📌 0


We show prompted models fail to change their behavior for different cost coefficients. But training leads to steerable models that get high reward – when increasing the cost of turns, models ask less questions. When the price of tokens is high, models avoid multi. answers
06.03.2026 00:24
👍 0
🔁 0
💬 1
📌 0

We test this in two question answering settings, (a) when the AI assistant uses parameterized knowledge and (b) When the AI assistant has access to privately-held information.
06.03.2026 00:24
👍 0
🔁 0
💬 1
📌 0

In this work, we train steerable models – models take as input in their prompt scalar values that reflect different costs (cost of each token, cost of each turn) and are trained to maximize their cost-penalized accuracy through collaborative self-play with a user simulator.
06.03.2026 00:24
👍 1
🔁 0
💬 1
📌 0

Newish work (arXived in December):
Prompts can be ambig., but handling ambiguity is context/user dependent. Sometimes the right thing is to ask a clarifying question, sometimes to give multi. answers, and sometimes to just guess. Can we train steerable models that change their strategy per context?
06.03.2026 00:24
👍 2
🔁 1
💬 1
📌 1


AI systems are also overconfident, terminating dialogues long before exhausting their turn budget - even after explicit reminders.
04.03.2026 00:15
👍 8
🔁 1
💬 1
📌 0

So how well do today's models do?
To answer this, we design a new multi-turn scaling analysis, called *isotoken evaluation*: fix a total token budget, and partition it into variable numbers of turns.
Performance should be non-decreasing in the number of turns... and yet!
04.03.2026 00:15
👍 6
🔁 1
💬 1
📌 0

We believe these games are more naturalistic and proactive than most existing multi-turn evaluations, which often employ user simulators to create multi-turn user-assistant scenarios.
Here's another game, which requires answering a question about two privately-held images.
04.03.2026 00:15
👍 4
🔁 1
💬 1
📌 0

This task is part of 🏓MT-PingEval, a new benchmark of verifiable collaborative private information games that involve multi-turn dialogue.
In this game, the "describer" sees only a single image, and the "guesser" has to identify which one it is.
04.03.2026 00:15
👍 4
🔁 1
💬 1
📌 0

Are AI models effective collaborators, or mere assistants awaiting your next command? (Preprint: arxiv.org/abs/2602.24188)
To find out, we make AI collaborate with itself, in private information games: tasks that require sharing private information, like this chess board ordering task.
04.03.2026 00:15
👍 54
🔁 21
💬 3
📌 1
With GDM friends Adam Fisch, @jonathanberant.bsky.social, Alekh Agarwal, and special guest Anastasios Angelopoulos.
10.06.2025 15:24
👍 2
🔁 1
💬 0
📌 0
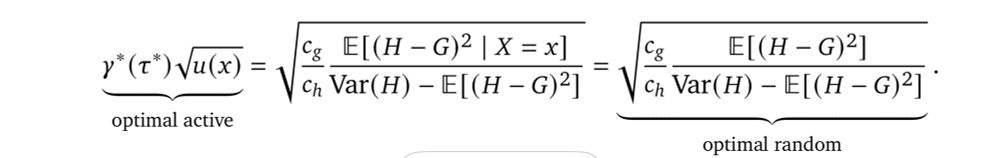
We offer cost-optimal policies for selecting which rater should annotate which examples, which link the cost, the annotation noise, and the *uncertainty* of the cheaper rater.
10.06.2025 15:24
👍 1
🔁 1
💬 1
📌 0
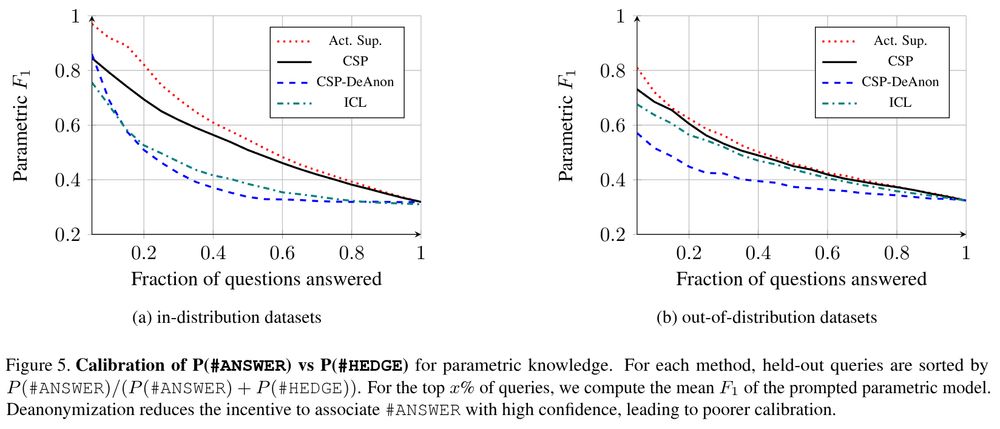
calibration of p(answer), which is learned only when the helper identity is anonymized
An ablation reveals the importance of mechanism design: when the helper identities are known to the asker during training (CSP-DeAnon), calibrated hedging is no longer learned.
24.03.2025 15:39
👍 6
🔁 1
💬 1
📌 0
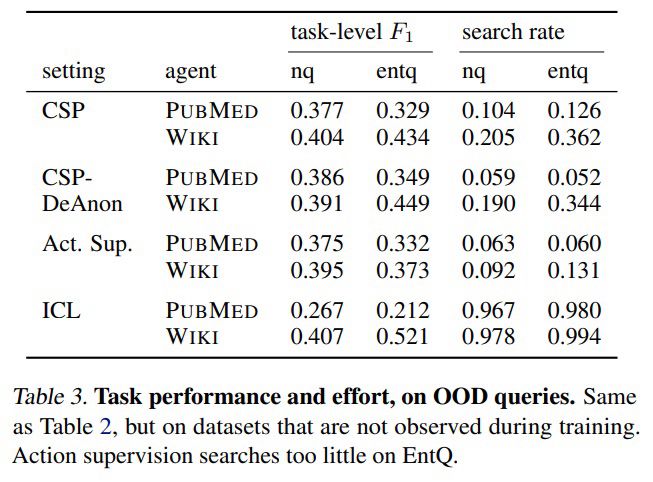
task f1 and tool use
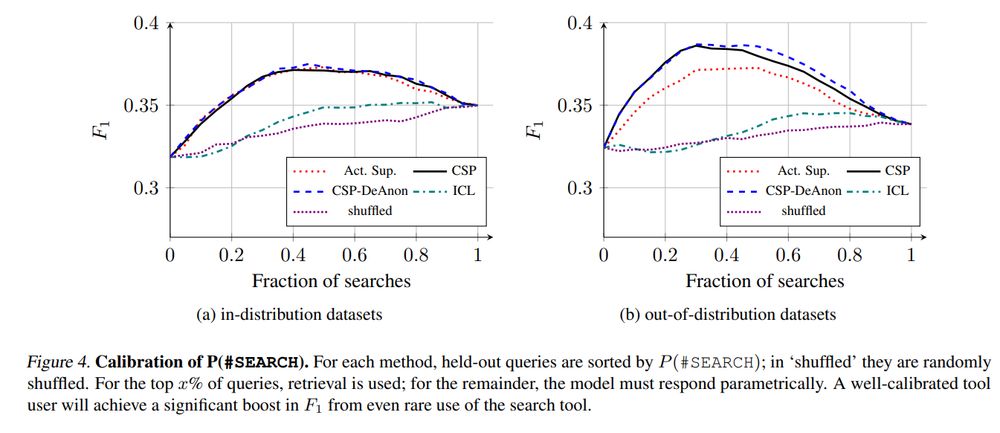
calibration curves for tool use, showing that collaborative self play teaches when to use the retrieval tools
In practice, collaborative self-play + reinforced self-training (ReST) lead to improved task performance, better calibration of confidence markers, and more efficient tool use.
24.03.2025 15:39
👍 5
🔁 1
💬 2
📌 0
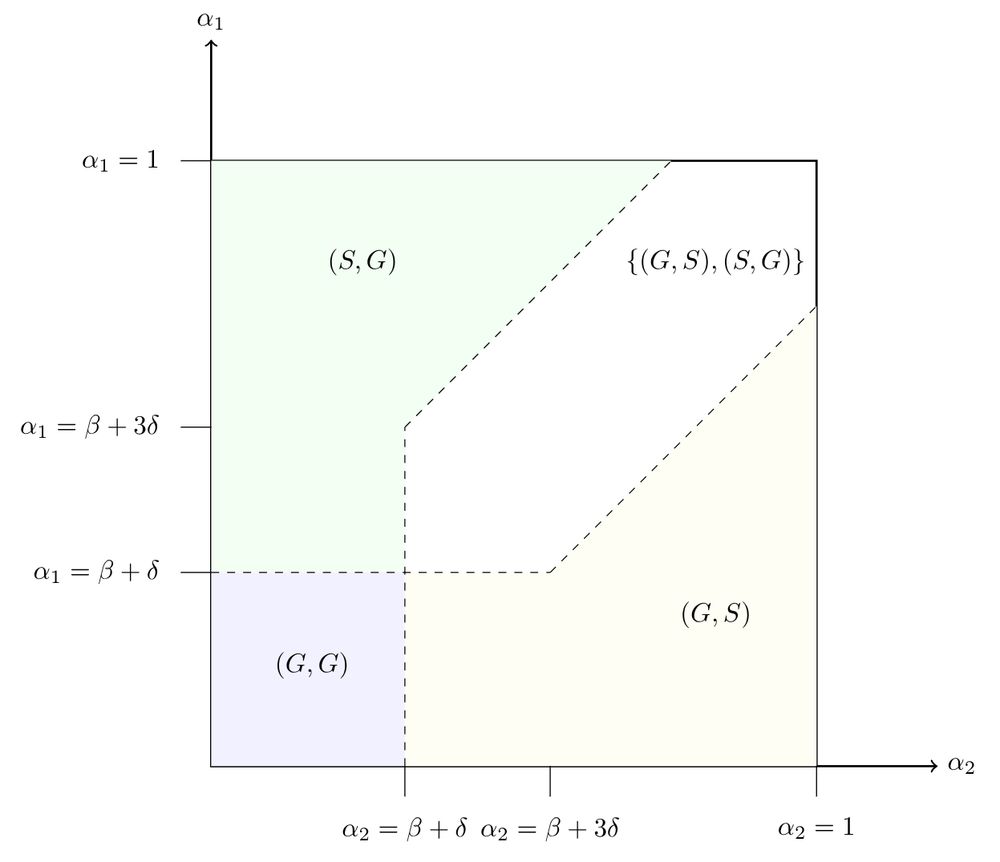
illustration of the equilibria of the formal model of costly information provision
A bit of game theory can help explain when this can work: we model the setup as a game of public utility provision, where the public utility is the extra information provided by the costly retrieval action. The game has a unique equilibrium when the tools are sufficiently distinct (or both bad).
24.03.2025 15:39
👍 4
🔁 1
💬 1
📌 0

an example rollout, in which the asker receives contrasting advice from its helpers, and must rely on their confidence to find the accurate response
Because the identity of each helper is hidden from the asker, it is forced to rely on confidence signals when faced with incompatible answers from the helpers. Maximizing effort-penalized accuracy of the full rollout can teach the LLM to use these confidence markers correctly.
24.03.2025 15:39
👍 3
🔁 1
💬 1
📌 0
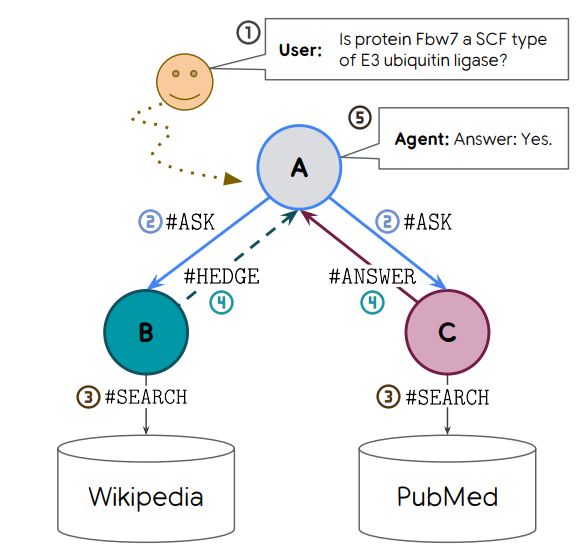
schematic illustrating the collaborative self play scenario
We focus on two capabilities: knowing when to use a costly retrieval tool, and hedging non-confident answers. To teach these capabilities, we create a small multi-agent society, in which two "helpers" can use specialized retrieval tools to pass information back to an "asker"
24.03.2025 15:39
👍 5
🔁 1
💬 1
📌 0

Don't lie to your friends: Learning what you know from collaborative self-play
Jacob Eisenstein, Reza Aghajani, Adam Fisch, Dheeru Dua, Fantine Huot, Mirella Lapata, Vicky Zayats, Jonathan Berant
To be helpful assistants, AI agents must be aware of their own capabilities and limitations. This includes knowing when to answer from parametric knowledge versus using tools, when to trust tool outputs, and when to abstain or hedge. Such capabilities are hard to teach through supervised fine-tuning because they require constructing examples that reflect the agent's specific capabilities. We therefore propose a radically new approach to teaching agents what they know: \emph{collaborative self-play}. We construct multi-agent collaborations in which the group is rewarded for collectively arriving at correct answers. The desired meta-knowledge emerges from the incentives built into the structure of the interaction. We focus on small societies of agents that have access to heterogeneous tools (corpus-specific retrieval), and therefore must collaborate to maximize their success while minimizing their effort. Experiments show that group-level rewards for multi-agent communities can induce policies that \emph{transfer} to improve tool use and selective prediction in settings where individual agents are deployed in isolation.
A way to help models "be aware of their own capabilities and limitations" from @jacobeisenstein.bsky.social et al: arxiv.org/abs/2503.14481 #MLSky
22.03.2025 16:09
👍 40
🔁 9
💬 3
📌 0
Fun work led by @amouyalsamuel.bsky.social and with Aya. Coming in I didn't think LLMs should have difficulties with answering questions on some of the GP sentences we used, but turns out they had! See Samuel's thread for more info...
12.03.2025 19:23
👍 0
🔁 0
💬 0
📌 0

One intriguing follow-up: some component of the sentence understanding cognitive model fails on GP sentence. Is this component also present in LLMs? If not, then why so many LLMs are influenced by our manipulations in the same way humans are?
12.03.2025 19:12
👍 1
🔁 1
💬 1
📌 0

There are many more cool insights you can find in our paper.
One takeaway from this paper for the psycholinguistics community: run your reading comprehension experiment on LLM first. You might get a general idea of the human results.
(Last image I swear)
12.03.2025 19:12
👍 1
🔁 1
💬 1
📌 0

These experiments replicated the results from the sentence comprehension one: our manipulations had the same effect on the paraphrase or drawing correctness as they had on the sentence comprehension task.
In this image: While the teacher taught the puppies looked at the board.
12.03.2025 19:12
👍 1
🔁 1
💬 2
📌 0

We also ran two additional experiments with LLMs that are challenging to perform on humans.
1. We asked the LLM to paraphrase our sentence
2. We asked text-to-image models to draw the sentences
In this image: While the horse pulled the submarine moved silently.
12.03.2025 19:12
👍 2
🔁 1
💬 1
📌 0
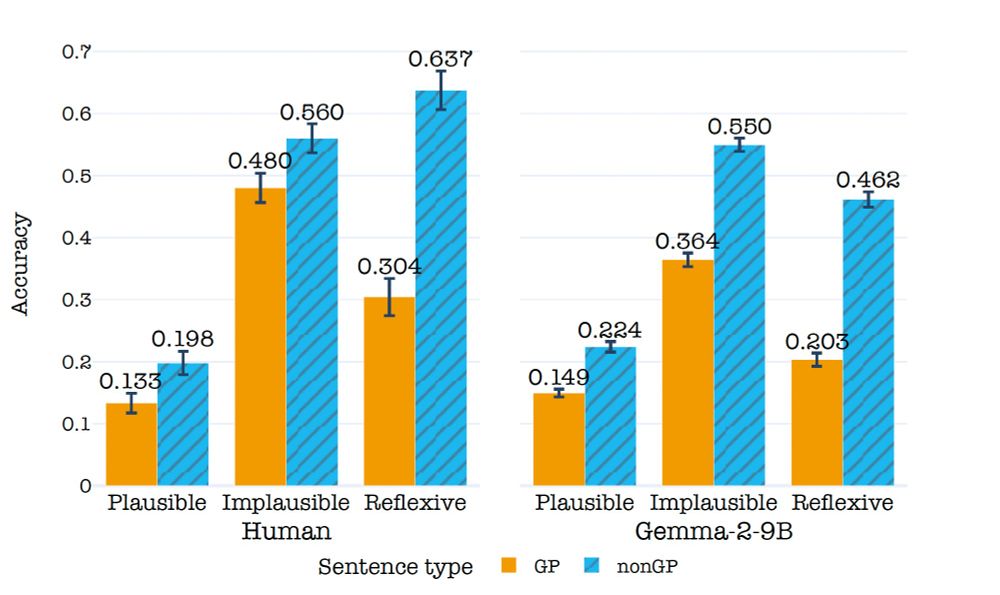
To answer our second question, we ran the same sentence comprehension experiment we ran on humans with over 60 LLMs.
We found that LLMs also struggle with GP sentences and that, interestingly, the manipulations we did to test our hypotheses impacted LLMs as they did with humans
12.03.2025 19:12
👍 1
🔁 1
💬 1
📌 0




