
Our AI & Scientific Discovery Workshop (@ NAACL 2025) broadly welcomes papers on all aspects of the scientific discovery process through the lens of AI / NLP.
Paper submission deadline: Jan 30/2025 (about 2 weeks).
We're excited to see you there!
15.01.2025 21:08
👍 3
🔁 1
💬 0
📌 3
Hey Marc! Thanks for this starter pack. Can you please add me to it as well?
29.11.2024 15:57
👍 7
🔁 0
💬 0
📌 0

AppWorld: Reliable Evaluation of Interactive Agents in a World of Apps and People. Happening at 11 AM EST online on Dec 2, 2024
🚨 Happening next Monday, 2 Dec, @cohere.com ! ✨
👋 Anyone can join remotely at this link:
👉 cohere.com/events/coher...
🙏 Thank you @sebruder.bsky.social for helping arrange it!!
📅 Upcoming talks: appworld.dev/talks
29.11.2024 15:43
👍 8
🔁 1
💬 0
📌 0

A plot: the x axis is baseline score of rankers, in ndcg@10. y axis is delta of model score after an expansion is applied.
There are three sets of results, one dataset for each shift type: TrecDL (no shift), FiQA (domain shift), ArguAna (query shift). For each set of result, the chart shows a scatter plot with a trend line. We observe the same trend for all: as the baseline score increases, the delta when using expansion decreases.
On TREC DL, worst models have a base score of ~40, and improve by 10 points w/expansion. the best models have a score of >70, and their performance decreases by -5 points w/expansion.
On FiQA, worse models have a base score of ~15, and improve by 5 points w/expansion. the best models have a score of ~45, and their performance decreases by -3 point w/expansion.
On ArguAna, worst models have a base score of ~25, and improve by >20 points w/expansion. the best models have a score of >55, and their performance decreases by -1 point w/expansion.
Using LLMs for query or document expansion in retrieval (e.g. HyDE and Doc2Query) have scores going 📈
But do these approaches work for all IR models and for different types of distribution shifts? Turns out its actually more 📉 🚨
📝 (arxiv soon): orionweller.github.io/assets/pdf/L...
15.09.2023 18:57
👍 42
🔁 6
💬 3
📌 3
Great opportunity to see how (your) new coding agent methods stack up real world user tasks
21.11.2024 23:51
👍 3
🔁 1
💬 0
📌 0
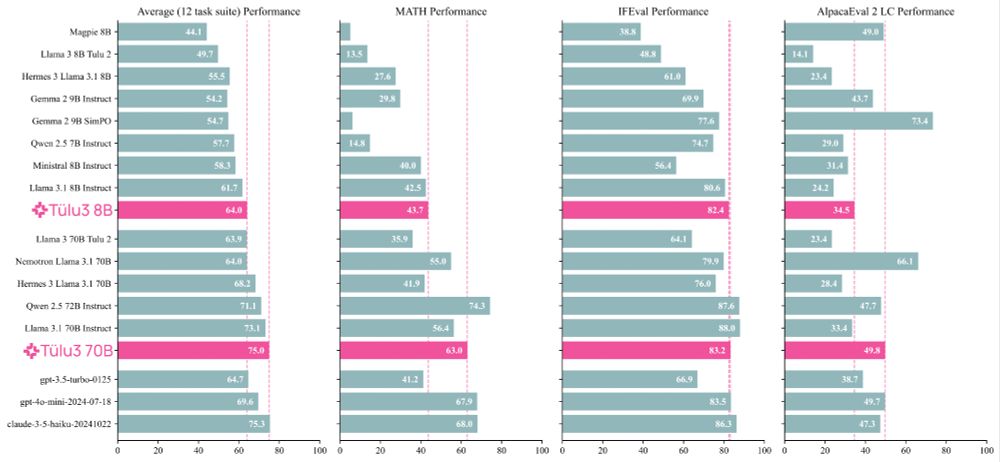
Meet Tülu 3, a set of state-of-the-art instruct models with fully open data, eval code, and training algorithms.
We invented new methods for fine-tuning language models with RL and built upon best practices to scale synthetic instruction and preference data.
Demo, GitHub, paper, and models 👇
21.11.2024 17:15
👍 111
🔁 31
💬 2
📌 7
another starter pack, this time for folks (past & current) from Ai2 (@ai2.bsky.social) 😍
go.bsky.app/Qjyc97J
21.11.2024 16:10
👍 22
🔁 5
💬 2
📌 0
I thought to create a Starter Pack for people working on LLM Agents. Please feel free to self-refer as well.
go.bsky.app/LUrLWXe
#LLMAgents #LLMReasoning
20.11.2024 14:08
👍 15
🔁 5
💬 11
📌 0
🚨 We are refreshing the 🌎 AppWorld (appworld.dev) leaderboard with all the new coding and/or tool-use LMs.
❓ What would you like to be included?
🔌 Self-plugs are welcome!!
x.com/harsh3vedi/s...
21.11.2024 14:11
👍 7
🔁 2
💬 0
📌 1
Hi Nikolai! Mind adding me to this starter pack? Thanks!
21.11.2024 13:05
👍 1
🔁 0
💬 1
📌 0
Hi! Can you please add me to this list? Thank you!
18.11.2024 22:56
👍 1
🔁 0
💬 0
📌 0
Hi Michael! Can you please add me to this list? Thank you!
18.11.2024 22:55
👍 2
🔁 0
💬 0
📌 0
Hi Maria! Can you please add me to the list? Thank you!
18.11.2024 22:53
👍 0
🔁 0
💬 0
📌 0
