
Coming up at ICML: 🤯Distribution shifts are still a huge challenge in ML. There's already a ton of algorithms to address specific conditions. So what if the challenge was just selecting the right algorithm for the right conditions?🤔🧵
07.07.2025 16:50
👍 6
🔁 1
💬 1
📌 0

ChatBotArena is far from the first eval to be overfit to. It's becoming underrated. Likely the single most impactful evaluation project since ChatGPT. The labs are the ones releasing these slightly off models.
28.04.2025 15:48
👍 7
🔁 2
💬 2
📌 0
Hiring two student researchers for Gemma post-training team at @GoogleDeepMind Paris! First topic is about diversity in RL for LLMs (merging, generalization, exploration & creativity), second is about distillation. Ideal if you're finishing PhD. DMs open!
26.03.2025 16:24
👍 4
🔁 1
💬 0
📌 0
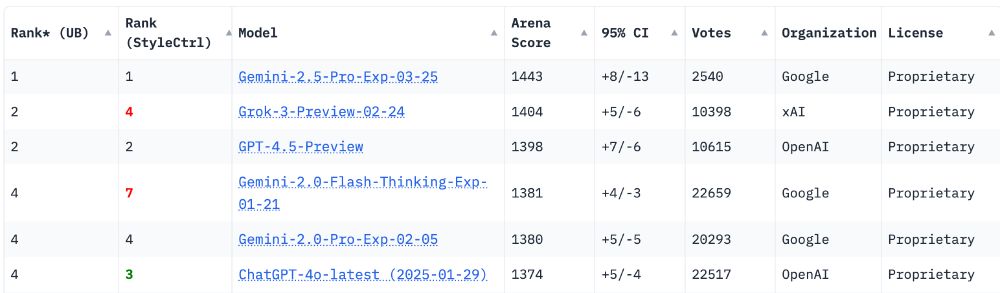

🥁Introducing Gemini 2.5, our most intelligent model with impressive capabilities in advanced reasoning and coding.
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
25.03.2025 17:25
👍 215
🔁 65
💬 34
📌 11

This is a very tidy little RL paper for reasoning. Their GRPO changes:
1 Two different clip hyperparams, so positive clipping can uplift more unexpected tokens
2 Dynamic sampling -- remove samples w flat reward in batch
3 Per token loss
4 Managing too long generations in loss
dapo-sia.github.io
17.03.2025 22:13
👍 26
🔁 4
💬 1
📌 0

Welcome Gemma 3, Google’s new open-weight LLM. All sizes (1B, 4B, 12B and 27B) excel on benchmarks, but the key result may be the 27B reaching 1338 on LMSYS. For this, we scaled post-training, with our novel distillation, RL and merging strategies.
Report: storage.googleapis.com/deepmind-med...
12.03.2025 09:03
👍 7
🔁 1
💬 0
📌 0
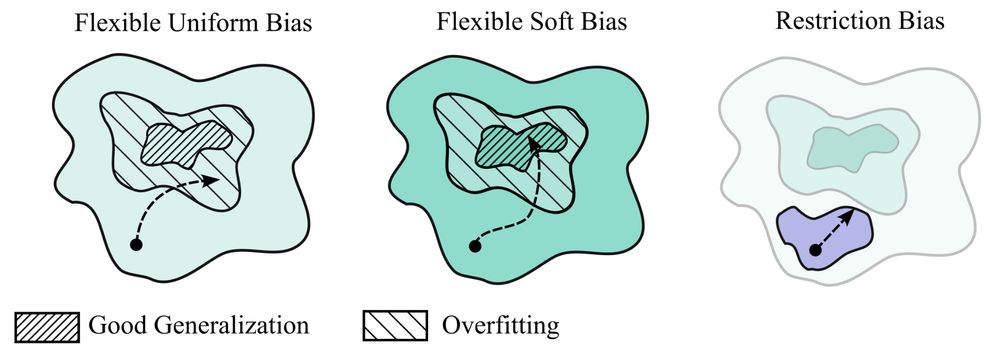
My new paper "Deep Learning is Not So Mysterious or Different": arxiv.org/abs/2503.02113. Generalization behaviours in deep learning can be intuitively understood through a notion of soft inductive biases, and formally characterized with countable hypothesis bounds! 1/12
05.03.2025 15:37
👍 210
🔁 49
💬 6
📌 9
Modern post-training is essentially distillation then RL. While reward hacking is well-known and feared, could there be such a thing as teacher hacking? Our latest paper confirms it. Fortunately, we also show how to mitigate it! The secret: diversity and onlineness! arxiv.org/abs/2502.02671
08.02.2025 18:06
👍 11
🔁 5
💬 0
📌 0
We just released the Helium-1 model , a 2B multi-lingual LLM which @exgrv.bsky.social and @lmazare.bsky.social have been crafting for us! Best model so far under 2.17B params on multi-lingual benchmarks 🇬🇧🇮🇹🇪🇸🇵🇹🇫🇷🇩🇪
On HF, under CC-BY licence: huggingface.co/kyutai/heliu...
13.01.2025 18:10
👍 25
🔁 8
💬 0
📌 0
ILYA: "PRETRAINING IS DONE. WE ARE NOW IN THE POST TRAINING ERA."
13.12.2024 22:49
👍 41
🔁 2
💬 3
📌 1

OpenAI's Reinforcement Finetuning and RL for the masses
The cherry on Yann LeCun’s cake has finally been realized.
Of all of OpenAI's days, the RL API is still the most revealing of the state of AI research trends. Lots of open doors for those looking at RL.
OpenAI's Reinforcement Finetuning and RL for the masses
The cherry on Yann LeCun’s cake has finally been realized.
11.12.2024 16:03
👍 14
🔁 3
💬 0
📌 0

🚨So, you want to predict your model's performance at test time?🚨
💡Our NeurIPS 2024 paper proposes 𝐌𝐚𝐍𝐨, a training-free and SOTA approach!
📑 arxiv.org/pdf/2405.18979
🖥️https://github.com/Renchunzi-Xie/MaNo
1/🧵(A surprise at the end!)
03.12.2024 16:58
👍 16
🔁 6
💬 2
📌 1

How to Apply — Department of Computer Science, University of Toronto
The right place for your phd:
With Colin Raffel, UofT works on decentralizing, democratizing, and derisking large-scale AI. Wanna work on model m(o)erging, collaborative/decentralized learning, identifying & mitigating risks, etc. Apply (deadline is Monday!)
web.cs.toronto.edu/graduate/how...
🤖📈
30.11.2024 11:49
👍 13
🔁 1
💬 0
📌 0
🥐 Building a Computer Vision FR Starter Pack!
👉 Who else should be included?
Comment below or DM me to be added
go.bsky.app/dfvcLZ
29.11.2024 09:18
👍 25
🔁 4
💬 4
📌 1

distributed learning for LLM?
recently, @primeintellect.bsky.social have announced finishing their 10B distributed learning, trained across the world.
what is it exactly?
🧵
25.11.2024 12:02
👍 23
🔁 6
💬 1
📌 2
This year, there are 16 positions at CNRS in computer science (8 in "applied" domains → ask me - 8 on "fundamental" domains → ask the other David).
@mathurinmassias.bsky.social has a good list of advice mathurinm.github.io/cnrs_inria_a...
Official 🔗 www.ins2i.cnrs.fr/en/cnrsinfo/...
Don't wait!
23.11.2024 19:33
👍 32
🔁 18
💬 2
📌 1
Feeling that Paris is "The Place To Be" for computer vision and AI in general.
21.11.2024 09:28
👍 18
🔁 2
💬 1
📌 0
My growing list of #computervision researchers on Bsky.
Missed you? Let me know.
go.bsky.app/M7HGC3Y
19.11.2024 23:00
👍 131
🔁 42
💬 88
📌 9
Bluesky now has over 20M people!! 🎉
We've been adding over a million users per day for the last few days. To celebrate, here are 20 fun facts about Bluesky:
19.11.2024 18:19
👍 130969
🔁 16167
💬 3087
📌 1407
New people in AI have joined recently, I can't cite all, but here are some: @fguney.bsky.social @natalianeverova.bsky.social @damienteney.bsky.social @jdigne.bsky.social @nbonneel.bsky.social @steevenj7.bsky.social @douillard.bsky.social @ramealexandre.bsky.social @stonet2000.bsky.social
1/
17.11.2024 22:22
👍 55
🔁 13
💬 4
📌 0






