Implementing a Unified NIH Funding Strategy to Guide Consistent and Clearer Award Decisions | Grants & Funding
As far as I can tell, the main point of this new NIH policy is that there will no longer be an explicit payline in any of the institutes. It's hard to see how this new policy makes the decision-making process "clearer for applicants."
grants.nih.gov/news-events/...
11.12.2025 07:08
👍 4
🔁 0
💬 1
📌 0
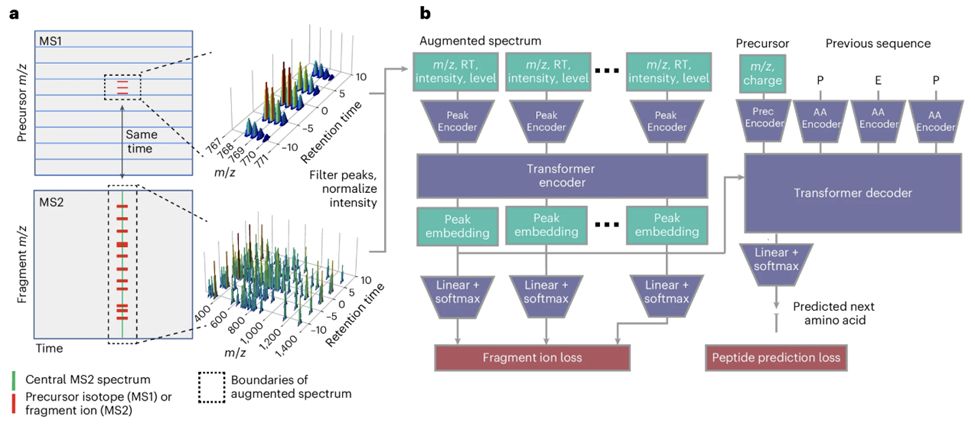
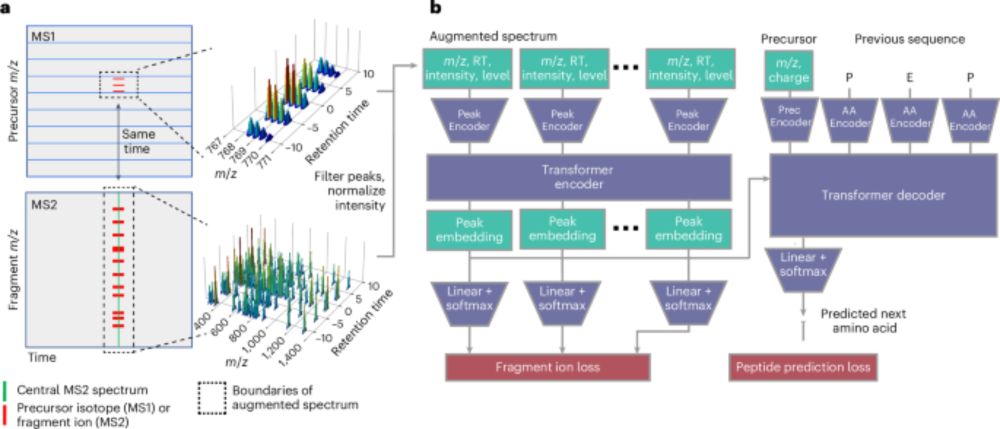
Cascadia from @wnoble.bsky.social is a mass spec-based de novo sequencing model that uses a transformer architecture to handle data-independent acquisition data and achieves substantially improved performance across a range of instruments and experimental protocols. www.nature.com/articles/s41...
07.07.2025 22:31
👍 13
🔁 4
💬 0
📌 0
Excited to see this published! It is a good step in the process for people to assess their FDR control in proteomics experiments. Great work from @bo-wen.bsky.social and @urikeich.bsky.social in particular who drove this.
16.06.2025 18:52
👍 42
🔁 9
💬 1
📌 1

Foundation model for mass spectrometry proteomics
Mass spectrometry is the dominant technology in the field of proteomics, enabling high-throughput analysis of the protein content of complex biological samples. Due to the complexity of the instrument...
Interested in prediction tasks involving peptide mass spectra? Our foundation model uses pre-trained spectrum representations learned by a de novo sequencing model to solve many tasks better and with less data, from recognizing chimeras to separating N- and O-glycopeptides. arxiv.org/abs/2505.10848
22.05.2025 11:49
👍 12
🔁 7
💬 0
📌 1
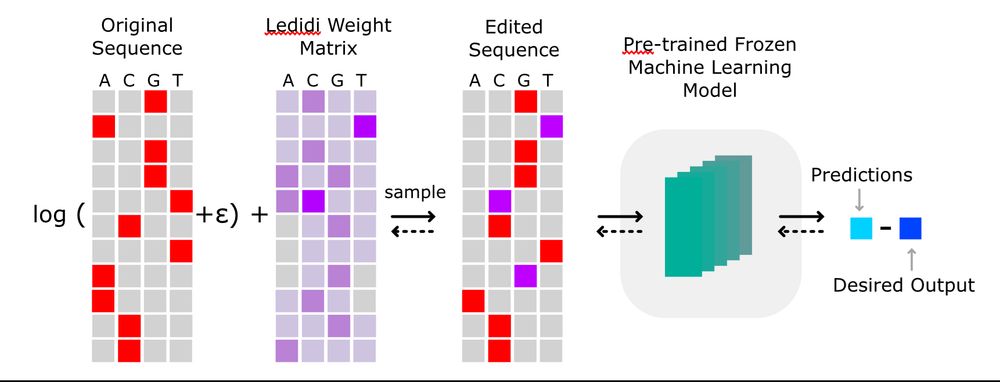
Ledidi turns any genomics ML model into a controllable sequence designer by inverting the normal ML paradigm. Now, it is significantly faster, flexible, and more powerful than before.
Available on GitHub and installable with `pip install ledidi`
07.01.2025 17:26
👍 58
🔁 10
💬 1
📌 3

A BLAST from the past: revisiting blastp’s E-value
AbstractMotivation. The Basic Local Alignment Search Tool, BLAST, is an indispensable tool for genomic research. BLAST established itself as the canonical
BLAST is a fantastic tool that has enabled sequence-driven discovery for over 30 years. But, alas, the E-value that it reports turns out to have some serious problems. Here we propose a fix. It's more computationally expensive, but computers are a bit faster than they were in 1990.
bit.ly/3ZDgYt8
06.12.2024 19:24
👍 11
🔁 3
💬 0
📌 0

Improved detection of differentially abundant proteins through FDR-control of peptide-identity-propagation
Quantitative analysis of proteomics data frequently employs peptide-identity-propagation (PIP) — also known as match-between-runs (MBR) — to increase the number of peptides quantified in a given LC-MS/MS experiment. PIP can routinely account for up to 40% of all quantitative results, with that proportion rising as high as 75% in single-cell proteomics. Therefore, a significant concern for any PIP method is the possibility of false discoveries: errors that result in peptides being quantified incorrectly. Although several tools for label-free quantification (LFQ) claim to control the false discovery rate (FDR) of PIP, these claims cannot be validated as there is currently no accepted method to assess the accuracy of the stated FDR. We present a method for FDR control of PIP, called “PIP-ECHO” (PIP Error Control via Hybrid cOmpetition) and devise a rigorous protocol for evaluating FDR control of any PIP method. Using three different datasets, we evaluate PIP-ECHO alongside the PIP procedures implemented by FlashLFQ, IonQuant, and MaxQuant. These analyses show that PIP-ECHO can accurately control the FDR of PIP at 1% across multiple datasets. Only PIP-ECHO was able to control the FDR in data with injected sample size equivalent to a single-cell dataset. The three other methods fail to control the FDR at 1%, yielding false discovery proportions ranging from 2–6%. We demonstrate the practical implications of this work by performing differential expression analyses on spike-in datasets, where different known amounts of yeast or E. coli peptides are added to a constant background of HeLa cell lysate peptides. In this setting, PIP-ECHO increases both the accuracy and sensitivity of differential expression analysis: our implementation of PIP-ECHO within FlashLFQ enables the detection of 53% more differentially abundant proteins than MaxQuant and 146% more than IonQuant in the spike-in dataset. ### Competing Interest Statement The authors have declared no competing interest.
Re-posting our new preprint on match between runs. This multi-lab effort (Keich, Noble, Payne & Smith) led by Alex Solivais should be of interest to anyone doing LFQ. We describe here how to control FDR in LFQ and provide the open source software to do it.
www.biorxiv.org/content/10.1...
02.12.2024 17:05
👍 31
🔁 15
💬 2
📌 2
We make two contributions in this paper: first, a method for ascertaining whether a given technique for peptide identity propagation successfully controls the FDR, and second, a new method, PIP-ECHO, that successfully does this.
02.12.2024 17:11
👍 0
🔁 0
💬 1
📌 0
When you analyze multiple protein samples in a single MS/MS experiment, it's common to do peptide identity propagation, rescuing peptides that fail to be identified in one run by mapping their coordinates (in time and m/z) from a different run in which those peptides were successfully identified.
02.12.2024 17:11
👍 0
🔁 0
💬 1
📌 0
The best place to do computational biology.
jobs.chronicle.com/job/37553144...
01.11.2023 16:32
👍 2
🔁 0
💬 0
📌 0
Er, let me get back to you on that. 😉
26.10.2023 22:51
👍 0
🔁 0
💬 0
📌 0
People don’t spend enough time looking at the trans contacts in their Hi-C data. There’s gold in them thar hills! www.biorxiv.org/content/10.1...
02.10.2023 20:13
👍 2
🔁 0
💬 0
📌 0