

Paper here: www.nature.com/articles/s41...
“Large Language Models forecast Patient Health Trajectories enabling Digital Twins”
07.10.2025 07:39
👍 0
🔁 0
💬 0
📌 0
Paper here: www.nature.com/articles/s41...
“Large Language Models forecast Patient Health Trajectories enabling Digital Twins”

Overall, DT-GPT shows that LLMs have the potential to become human digital twins. We hope that, in the future, LLM based digital twins will revolutionize the way we run clinical trials & patient care (10/10).
Check out the paper and appendix for many more results, including exploration of zero shot, various input parameters, latent clinical knowledge and tech details (9/10)

In zero shot forecasting, DT-GPT outperformed a fully trained model on 13 variables. These variables were typically biologically linked to the target variables used during training (8/10)
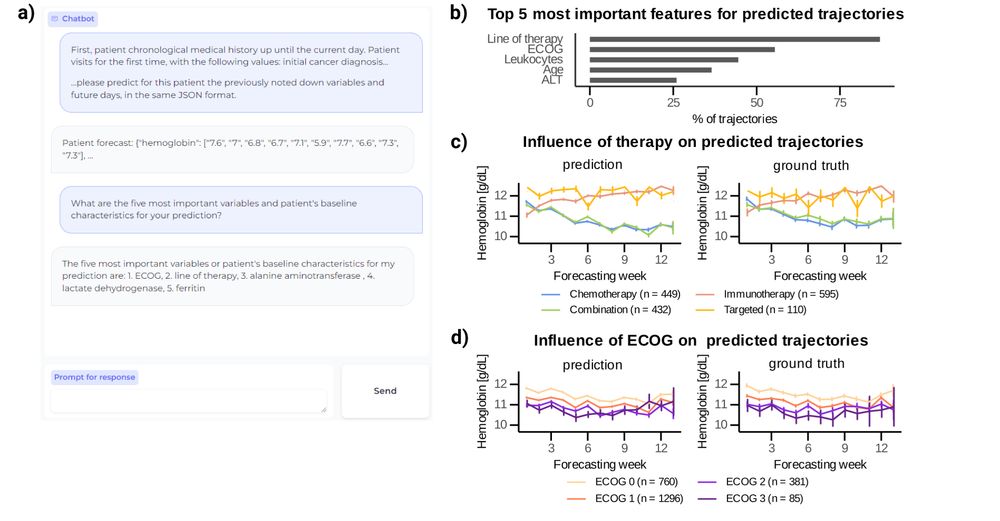
We show that key variables (e.g. therapy, ECOG) can drive differences in both predictions and real data. DT-GPT can even offer preliminary explainability & perform zero-shot on variables that it did not see during training. (7/10)

DT-GPT is robust: achieves competitive performance after ~5,000 patients, can even handle a 20% increase in missingness and up to 25 misspellings per sample without significant performance degradation (6/10)

Taking a step back, we see that DT-GPT also preserves the overall distribution of the outputs better than other baselines, quantified with the KS-distance (5/10)

Digging deeper, DT-GPT generally outperforms the second best model longitudinally. In many cases, high error predictions occur since our forecasts are based on aggregations of multiple trajectories, even if some individual trajectories are closer to the ground truth (4/10)
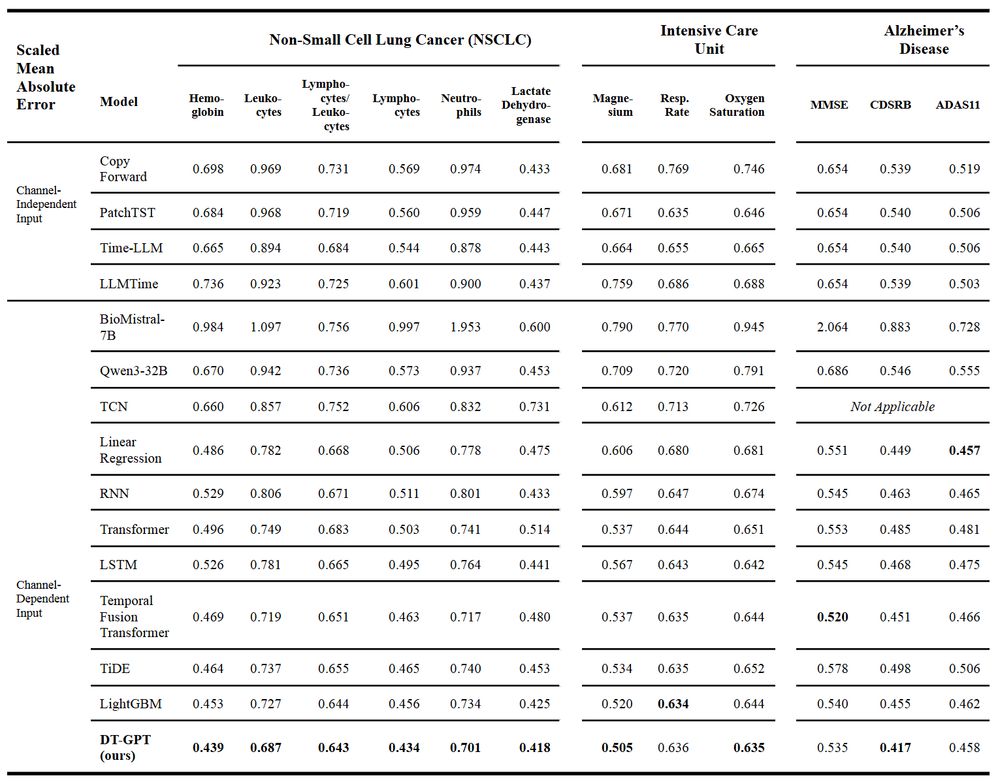
Our method, DT-GPT, outperforms the SOTA baselines in most cases, or achieves very competitive performance. Here you see the mean absolute error (MAE) across 12 variables in 3 different indications (3/10)

We fine-tune biomedical LLMs on patient clinical data, exploring the method on both a long term lung cancer dataset, and a short term ICU dataset. A few adjustments are required to get full performance, esp. trajectory aggregation & instruction masking (2/10)

DT-GPT: showing that LLMs can forecast patient trajectories (1/10)
Now in npj Digital Medicine www.nature.com/articles/s41...
Also in Doctor Penguin!
Big thanks to Maria Bordukova, @raulrod.bsky.social Papichaya Quengdaeng Daniel Garger @fschmich.bsky.social Michael Menden Helmholtz Munich Roche

A new model, DT-GPT, uses LLMs to forecast patient health trajectories, enabling "digital twins." By processing raw EHR data, it outperformed state-of-the-art methods in cancer, ICU, and Alzheimer's cohorts and can even forecast untrained variables.
#MedSky #MedAI #MLSky

[1/4] 🎉 We're thrilled to announce the general release of three de-identified, longitudinal EHR datasets from Stanford Medicine—now freely available for non-commercial research use worldwide! 🚀
Learn more on our HAI blog:
hai.stanford.edu/news/advanci...
Want to push the limits of LLMs in drug development?
🚀Apply now for our 2 summer internships for 2025:
1️⃣ Multimodal - www.linkedin.com/jobs/view/40...
2️⃣ Preclinical - www.linkedin.com/jobs/view/40...
DM me if you have any questions or know anybody who would be interested in this.

For my fellow researchers in AI, Medical, and Healthcare domain:, Here is the Medical AI Startup pack if you are new there
go.bsky.app/PddA2uy
Thanks!
This is great! Would it be possible to add me to this? 🙏
I created a starter pack for Health AI and Informatics. Mix of folks (reporters and researchers) that I think you should follow.
I've got room to include more, so please tag anyone you think I should add! 🧪🩺 🤖 🛟
Thank you!
This is fantastic! Would it be possible to add me in as well?
Thanks!!

Pre-print here: medrxiv.org/content/10.1...
“Large Language Models forecast Patient Health Trajectories enabling Digital Twins”
Reposted from X to have some content here :)
Overall, DT-GPT shows that LLMs have the potential to become human digital twins. We hope that, in the future, LLM based digital twins will revolutionize the way we run clinical trials & patient care (8/8).

In zero shot forecasting, DT-GPT outperformed a fully trained model on 13 variables. These variables were typically biologically linked to the target variables used during training (7/8)

DT-GPT can offer preliminary explainability & perform zero-shot on variables that it did not see during training. We show that key variables (e.g. therapy, ECOG) can drive differences in both predictions and real data (6/8)
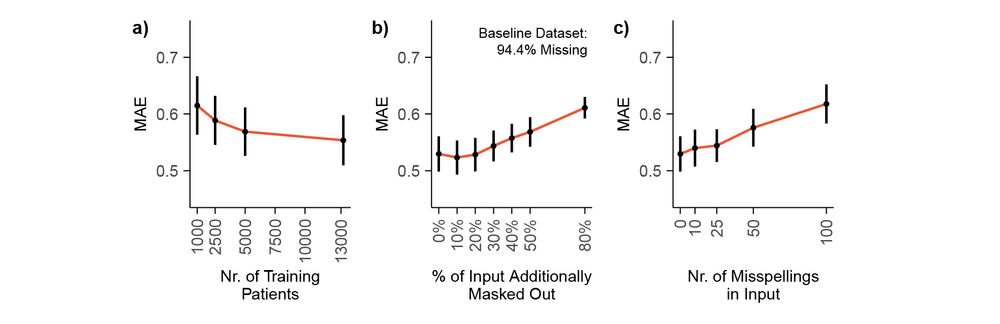
DT-GPT is robust: achieves competitive performance after ~5,000 patients, can even handle a 20% increase in missingness and up to 25 misspellings per sample without significant performance degradation (5/8)

Digging deeper, DT-GPT generally outperforms the second best model longitudinally. In many cases, high error predictions occur since our forecasts are based on aggregations of multiple trajectories, even if some individual trajectories are closer to the ground truth (4/8)

Our method, DT-GPT, outperforms the SOTA baselines in most cases, or achieves very competitive performance. Here you see the mean absolute error (MAE) across 9 variables (3/8)

We fine-tune biomedical LLMs on patient clinical data, exploring the method on both a long term lung cancer dataset, and a short term ICU dataset. A few adjustments are required to get full performance, esp. trajectory aggregation & instruction masking (2/8)

Introducing DT-GPT: showing that LLMs can forecast patient trajectories (1/8)
Pre-print here 👉 medrxiv.org/content/10.1...
Big thanks to Maria Bordukova, @raulrod.bsky.social, Fabian Schmich, Michael Menden, UniMelb, HelmholtzMunich, Roche