Shikhar Bharadwaj, Chin-Jou Li, Yoonjae Kim, Kwanghee Choi, Eunjung Yeo, Ryan Soh-Eun Shim, Hanyu Zhou, Brendon Boldt, Karen Rosero Jacome, Kalvin Chang, Darsh Agrawal, Keer Xu, ...
PRiSM: Benchmarking Phone Realization in Speech Models
https://arxiv.org/abs/2601.14046
21.01.2026 09:30
👍 0
🔁 1
💬 0
📌 0
Bharadwaj, Li, Kim, Choi, Yeo, Shim, Zhou, Boldt, Jacome, Chang, Agrawal, Xu, Yang, Zhu, Watanabe, Mortensen: PRiSM: Benchmarking Phone Realization in Speech Models https://arxiv.org/abs/2601.14046 https://arxiv.org/pdf/2601.14046 https://arxiv.org/html/2601.14046
21.01.2026 06:32
👍 0
🔁 2
💬 0
📌 0

Can we make discrete speech units lightweight🪶 and streamable🏎? Excited to share our new #Interspeech2025 paper: On-device Streaming Discrete Speech Units arxiv.org/abs/2506.01845 (1/n)
15.08.2025 20:44
👍 1
🔁 1
💬 2
📌 0
Meows, music, murmurs and more - we trained a general purpose audio encoder and open sourced the code, checkpoint and evaluation toolkit.
22.07.2025 03:36
👍 3
🔁 0
💬 0
📌 0

📢 We've open-sourced NatureLM-audio, the first audio-language foundation model for #bioacoustics.
Trained on large-scale animal vocalization, human speech & music datasets, the model enables zero-shot classification, detection & querying across diverse species & environments 👇🏽
24.04.2025 15:54
👍 27
🔁 12
💬 2
📌 0
🔗 Resources for ESPnet-SDS:
📂 Codebase (part of ESPnet): github.com/espnet/espnet
📖 README & User Guide: github.com/espnet/espne...
🎥 Demo Video: www.youtube.com/watch?v=kI_D...
17.03.2025 14:29
👍 1
🔁 1
💬 0
📌 0
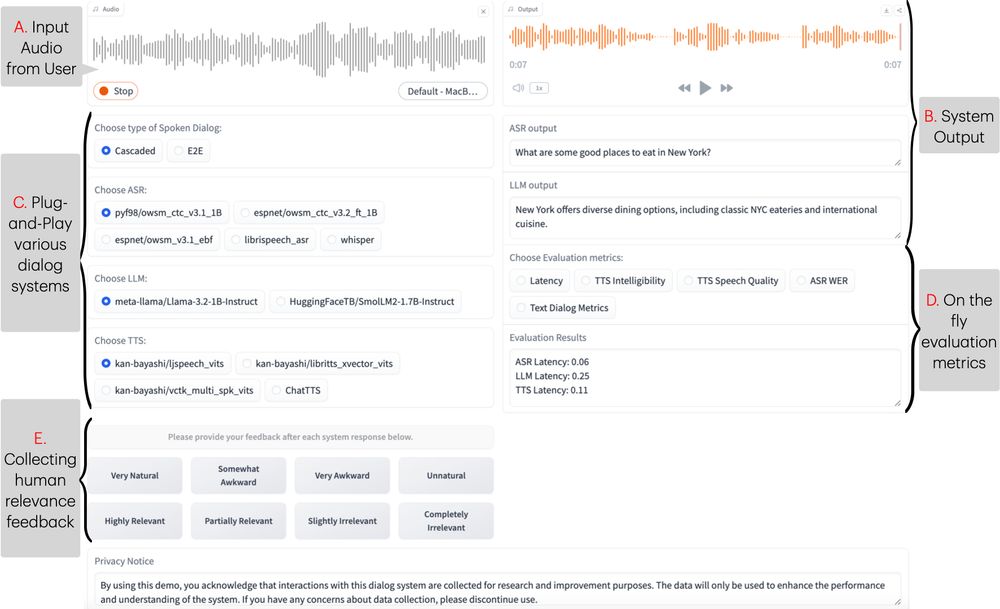
New #NAACL2025 demo, Excited to introduce ESPnet-SDS, a new open-source toolkit for building unified web interfaces for both cascaded & end-to-end spoken dialogue system, providing real-time evaluation, and more!
📜: arxiv.org/abs/2503.08533
Live Demo: huggingface.co/spaces/Siddh...
17.03.2025 14:29
👍 7
🔁 5
💬 1
📌 0
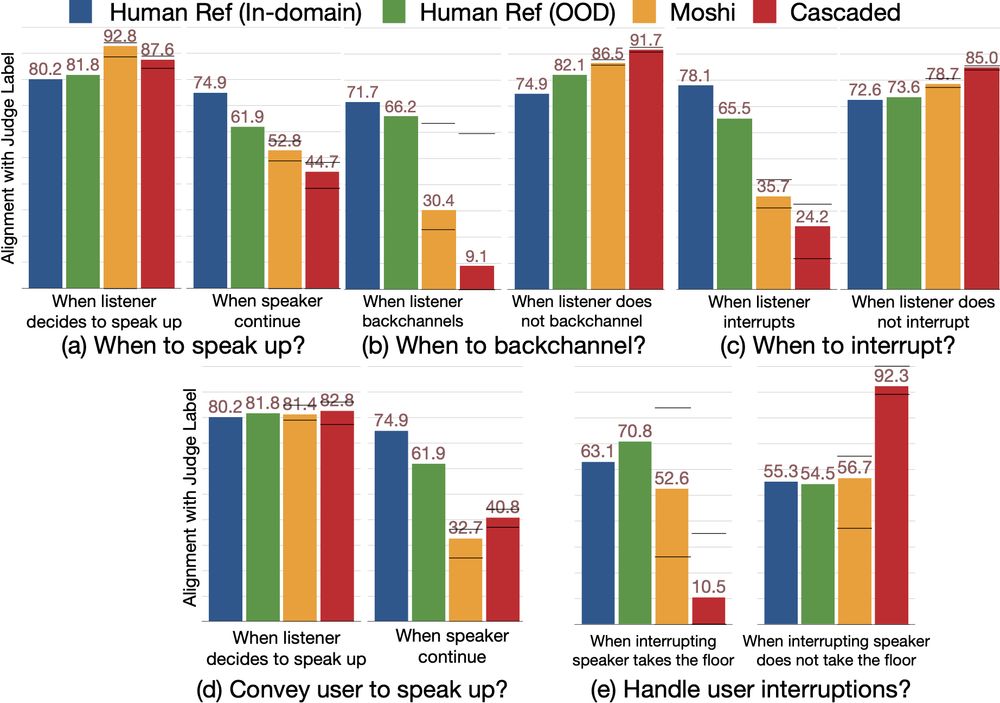
🚀 New #ICLR2025 Paper Alert! 🚀
Can Audio Foundation Models like Moshi and GPT-4o truly engage in natural conversations? 🗣️🔊
We benchmark their turn-taking abilities and uncover major gaps in conversational AI. 🧵👇
📜: arxiv.org/abs/2503.01174
05.03.2025 16:03
👍 9
🔁 6
💬 1
📌 0
Wait I thought the rock was named Dwayne Johnson
06.02.2025 13:29
👍 0
🔁 0
💬 0
📌 0
gpu poverty is real
28.01.2025 05:10
👍 2
🔁 0
💬 1
📌 0
Happy New Year
02.01.2025 23:21
👍 23823
🔁 4475
💬 386
📌 313
Philip Whittington, Gregor Bachmann, Tiago Pimentel
Tokenisation is NP-Complete
https://arxiv.org/abs/2412.15210
20.12.2024 05:18
👍 2
🔁 1
💬 0
📌 0

Today, we’re introducing NatureLM-audio: the first large audio-language model tailored for understanding animal sounds. arxiv.org/abs/2411.07186 🧵👇
05.12.2024 00:45
👍 15
🔁 8
💬 2
📌 4
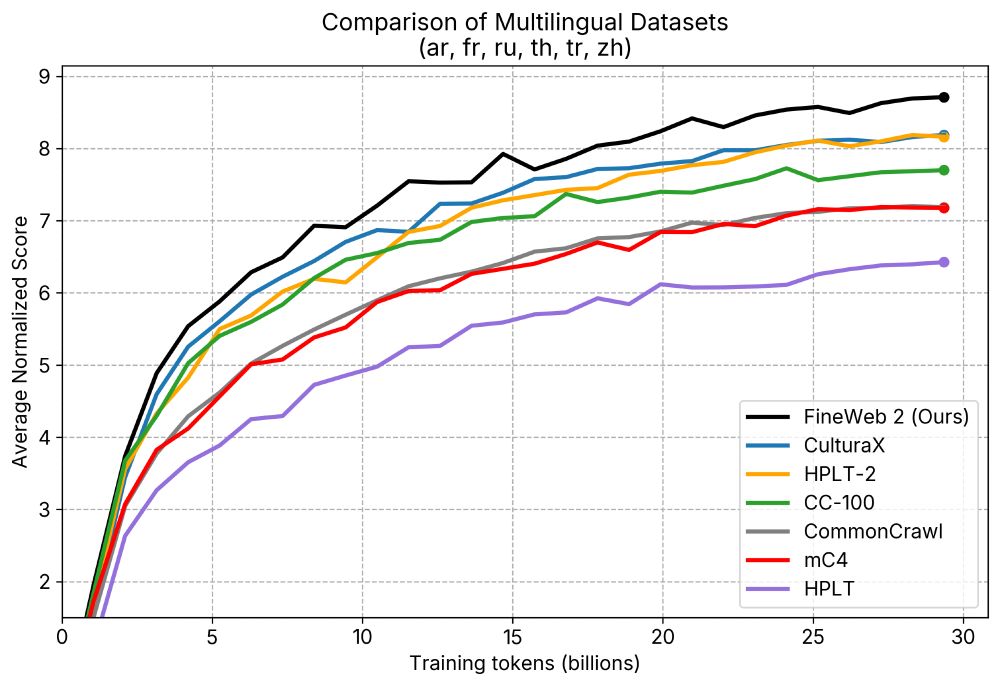
Announcing 🥂 FineWeb2: A sparkling update with 1000s of 🗣️languages.
We applied the same data-driven approach that led to SOTA English performance in🍷 FineWeb to thousands of languages.
🥂 FineWeb2 has 8TB of compressed text data and outperforms other datasets.
08.12.2024 09:19
👍 76
🔁 19
💬 1
📌 0
WAVLab is up in bsky!
06.12.2024 19:15
👍 8
🔁 2
💬 0
📌 0
🙋♂️
30.11.2024 16:55
👍 0
🔁 0
💬 0
📌 0
I've started putting together a starter pack with people working on Speech Technology and Speech Science: go.bsky.app/BQ7mbkA
(Self-)nominations welcome!
19.11.2024 11:13
👍 82
🔁 34
💬 44
📌 3

Examples from dataset, a world map surrounded by spectrograms showing animal sounds from different regions of the world

Scatter plot where points are sound data sets, x axis is number of categories in dataset and y axis is duration of dataset in hours
iNatSounds is shown as the largest dataset on both axes
iNatSounds: new dataset from folks @inaturalist.bsky.social & co-authors; looks to be one of the largest public datasets of animal sounds
openreview.net/forum?id=QCY...
github.com/visipedia/in...
#prattle 💬
#bioacoustics
29.11.2024 03:30
👍 30
🔁 14
💬 1
📌 5
🙋♂️🙏
24.11.2024 23:49
👍 1
🔁 0
💬 0
📌 0
🙋♂️🙏
24.11.2024 23:44
👍 0
🔁 0
💬 0
📌 0
🙋♂️
23.11.2024 00:36
👍 0
🔁 0
💬 0
📌 0
We're here too now! 🥳
22.11.2024 14:42
👍 8
🔁 6
💬 0
📌 0
Me (shikharb@bsky.social) and our lab bsky.app/profile/wavl...
22.11.2024 23:09
👍 1
🔁 0
💬 0
📌 0





