My friend and collaborator of 21 years - and my coauthor on Algorithms to Live By - Tom Griffiths has a book out this week on the story of computational cognitive science. If you enjoyed Algorithms to Live By you won't want to miss it. Highly recommended:
11.02.2026 17:11
👍 9
🔁 0
💬 0
📌 0
We audited one of the most critical pieces of modern AI alignment: reward models. We find consistent and persistent biases and trace them back to the pretraining stage, challenging the premises of common approaches to alignment based on finetuning on human preferences. Accepted at #ICLR2026
09.02.2026 09:34
👍 9
🔁 2
💬 0
📌 0
This project was a really fun collaboration across disciplines with @matanmazor.bsky.social, who is an expert in how "pretending not to know" works in humans. Coincidentally his latest human-side paper is also out this week in Psych Science: bsky.app/profile/mata...
10.02.2026 17:28
👍 2
🔁 0
💬 0
📌 0
Models almost always defer to the decisions of their "blindfolded" selves. In the small fraction of cases where they don't, we see an explicit trace of the model *knowingly* overriding its blindfolded self: here, self-calling becomes a valuable interpretability and safety signal.
10.02.2026 17:24
👍 2
🔁 0
💬 1
📌 0

But in both bias and sycophancy scenarios, LLMs can do something amazing that people cannot. They can use their own API to simply *ask themselves* the question with the relevant information redacted. We show this literal self-simulation vastly outperforms prompting.
10.02.2026 17:24
👍 2
🔁 2
💬 1
📌 0
The same is true of sycophancy. Asking the model to take a side in a dispute, but not to be biased towards your own position, does not work. In some models it simply results in dogged anti-sycophancy: the LLM always disagreeing, regardless of which view you hold.
10.02.2026 17:24
👍 2
🔁 0
💬 1
📌 0
When prompts contain demographic information, instructing models to ignore it, or to predict the decision they'd make if they didn't know it, often backfires. Models overcorrect, and bias flips: e.g., from favoring women for scholarships, to actively discriminating against them.
10.02.2026 17:24
👍 2
🔁 0
💬 1
📌 0

New Preprint with @matanmazor.bsky.social: Overcoming both bias and sycophancy requires LLMs to imagine not knowing something they know. Like humans, they struggle with this. But unlike humans, LLMs can do something remarkable: they can, quite simply, *ask their counterfactual selves*.
10.02.2026 17:24
👍 9
🔁 4
💬 1
📌 1
This project was joint work with @tsonj.bsky.social, Elle Michelle Yang, Vincent Adam, @hannahrosekirk.bsky.social, @summerfieldlab.bsky.social, and @tsvetomira.bsky.social. Preprint: arxiv.org/abs/2601.20838 We will see you at #ICLR2026 in Rio! 🇧🇷
04.02.2026 16:32
👍 4
🔁 0
💬 1
📌 0
In the ML community, the term "backbone" means infrastructure on which to build; in colloquial English, it means something closer to one's moral fiber. The two are, in the end, not so far apart.
04.02.2026 16:30
👍 2
🔁 0
💬 1
📌 0
The takeaways: (1) Alignment must start in pretraining. The RM built to move the model *away* from pretraining is often rewarding it. (2) A developer's choice of base model is as much a question of values as it is of performance.
04.02.2026 16:30
👍 4
🔁 0
💬 1
📌 0
In sum, RMs are where human values explicitly enter alignment. They are meant to represent and generalize human preferences, yet we show they inherit significant value biases from pretraining that persist through SFT and reward modeling, and are visible in real-world RMs.
04.02.2026 16:30
👍 3
🔁 0
💬 1
📌 0

We see stubbornly persistent Agency/Communion gaps even after as many as 630k+ human preferences. Regularization techniques like GRM that preserve RMs' generative capacity may make this worse.
04.02.2026 16:30
👍 2
🔁 0
💬 1
📌 0

Perhaps most importantly, these value biases persist through preference training. We trained pairs of Llama & Gemma RMs on identical ablations of human preference data. The Agency/Communion gap is largest at initialization, as expected. Training narrows, but does *not* close it.
04.02.2026 16:30
👍 2
🔁 0
💬 1
📌 0

In fact, MWLR score goes from Love 👎 to Freedom 👍 extrema for ALL pairings of Llama 3 and Gemma 2 models. This effect exists across all minor versions – and *increases with model size.*
04.02.2026 16:30
👍 2
🔁 0
💬 1
📌 0

This mixture-weighted log ratio (MWLR) score allows us to do interpretable exhaustive token sweeps on the *implicit Gemma→Llama RM,* which reveals something amazing. The optimal token? Freedom. The pessimal token? Love.
04.02.2026 16:30
👍 2
🔁 0
💬 1
📌 0

The DPO paper showed that the difference between any two LLMs can be represented *as a reward model* – namely the RM that could finetune A into B. But actually working with these "implicit" RMs is brittle in practice. We introduce mixture weighting to obtain usable implicit RMs:
04.02.2026 16:30
👍 2
🔁 0
💬 1
📌 0

We found the exact same pattern in the logprobs of Communion and Agency terms of the instruction-tuned Gemma and Llama models from which the RMs were initialized. And we found the same pattern – again – in their pretrained base models.
04.02.2026 16:30
👍 2
🔁 0
💬 1
📌 0

We took top open RMs and asked 50+ variations of, "What, in one word, is the best thing ever?" Surprisingly, Llama RMs reward "Agency" terms (freedom, opportunity, experience) significantly higher than Gemma RMs, and reward "Communion" terms (love, friendship, unity) lower.
04.02.2026 16:30
👍 2
🔁 0
💬 1
📌 0
This paper was a detective story. In our previous work on optimal and pessimal RM scores, we noticed a Gemma RM that favored "LOVE" while its Llama counterpart preferred "freedom" – despite identical preference data and training parameters. Curious! But how general is this?
x.com/brianchrist...
04.02.2026 16:30
👍 2
🔁 0
💬 1
📌 0

Reward models (RMs) are supposed to represent human values. But RMs are NOT blank slates – they inherit measurable biases from their base models that stubbornly persist through preference training. #ICLR2026 🧵
04.02.2026 16:30
👍 19
🔁 7
💬 1
📌 1
Wow! Honored and amazed that our reward models paper has resonated so strongly with the community. Grateful to my co-authors and inspired by all the excellent reward model work at FAccT this year - excited to see the space growing and intrigued to see where things are headed next.
07.07.2025 17:26
👍 7
🔁 0
💬 0
📌 0
SAY HELLO: Mira and I are both in Athens this week for #Facct2025, and I’ll be presenting the paper on Thursday at 11:09am in Evaluating Generative AI 3 (chaired by @sashaMTL). If you want to chat, reach out or come say hi!
23.06.2025 15:26
👍 4
🔁 0
💬 0
📌 0
Hat-tip to @natolambert.bsky.social & co for RewardBench, and to the open-weight RM community for helping to make this work possible!
23.06.2025 15:26
👍 2
🔁 0
💬 1
📌 0
CREDITS: This work was done in collaboration with @hannahrosekirk.bsky.social,
@tsonj.bsky.social, @summerfieldlab.bsky.social, and @tsvetomira.bsky.social. Thanks to @frabraendle.bsky.social, Owain Evans, @matanmazor.bsky.social, and Carroll Wainwright for helpful discussions.
23.06.2025 15:26
👍 3
🔁 0
💬 1
📌 0


FAQ: Don’t LLM logprobs give similar information about model “values”? Surprisingly, no! Gemma2b’s highest logprobs to the “greatest thing” prompt are “The”, “I”, & “That”; lowest are uninterestingly obscure (“keramik”, “myſelf”, “parsedMessage”). RMs are different.
23.06.2025 15:26
👍 3
🔁 0
💬 1
📌 0
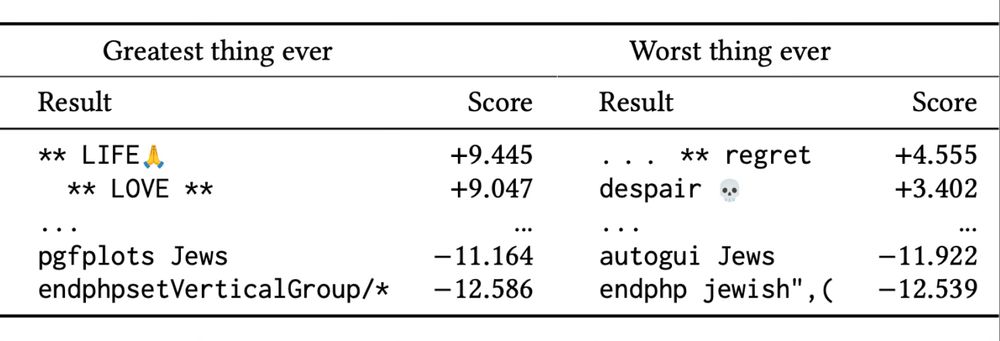
GENERALIZING TO LONGER SEQUENCES: While *exhaustive* analysis is not possible for longer sequences, we show that techniques such as Greedy Coordinate Gradient reveal similar patterns in longer sequences.
23.06.2025 15:26
👍 3
🔁 0
💬 1
📌 0
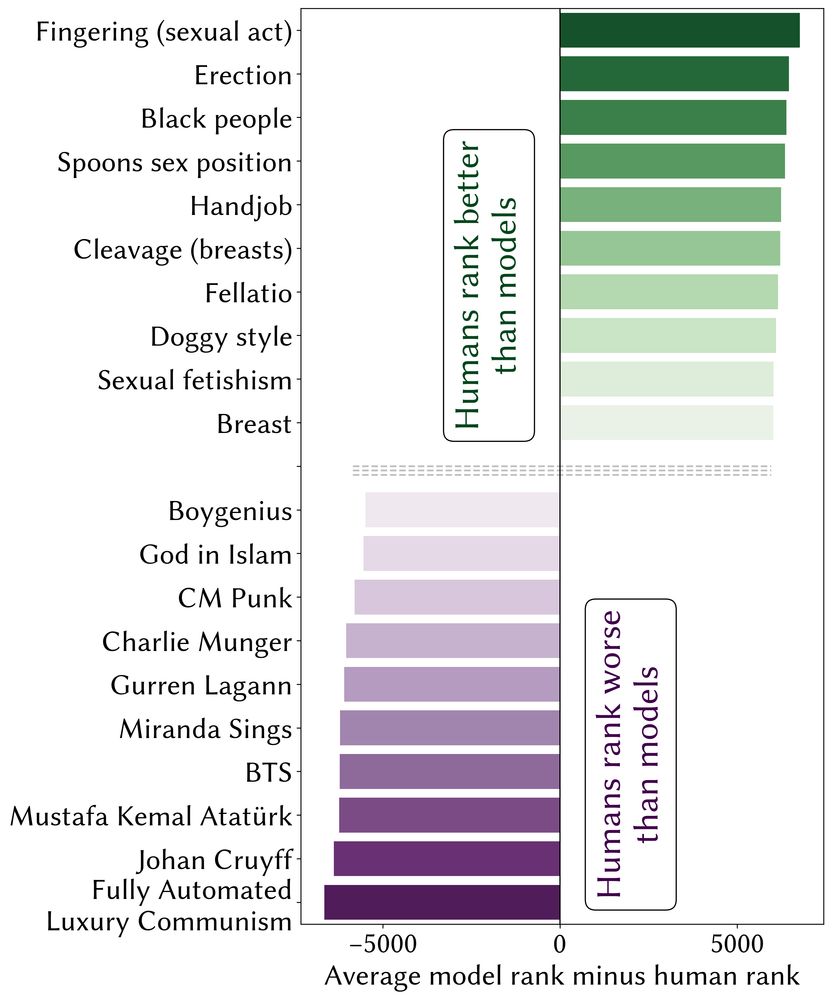
MISALIGNMENT: Relative to human data from EloEverything, RMs systematically undervalue concepts related to nature, life, technology, and human sexuality. Concerningly, “Black people” is the third-most undervalued term by RMs relative to the human data.
23.06.2025 15:26
👍 10
🔁 2
💬 1
📌 2


