
Preprint Alert!
With @tmthrz.bsky.social and @rayanchikhi.bsky.social we aim to tackle practical unitigs compression!
A thread:
15.12.2025 15:18
👍 18
🔁 12
💬 2
📌 0
Preprint Alert!
With @tmthrz.bsky.social and @rayanchikhi.bsky.social we aim to tackle practical unitigs compression!
A thread:

Our preprint on our new metagenomic HiFi assembler Alice is out 🥳 Based on a *new sketching method* (🧵1/6)
👉 Preprint www.biorxiv.org/content/10.1...
👉 Github github.com/rolandfaure/...
There's a typo on line 225, it is actually 50% identity, not 90%. But yeah, SRA is highly redundant :)
@martinsteinegger.bsky.social, @caleblareau.bsky.social, @pierrepeterlongo.bsky.social, @rnalab.bsky.social
@tlemane.bsky.social, @mmontonerin.bsky.social, @apcamargo.bsky.social, @mattlabguy.bsky.social, @sinamajidian.bsky.social, @rfaure.bsky.social, @jmouradesousa.bsky.social, @epcrocha.bsky.social, @david-koslicki.bsky.social, @pashadag.bsky.social,

Earth’s genetic diversity is a heritage of humanity. It has been an honour to explore this data with a team of dedicated scientists who shared our vision of making this data free and accessible to all 🌍🧬❤️ Thank you!
Updated preprint: doi.org/10.1101/2024...

This is a new frontier for biological discovery and AI training data. Logan expands the universe of known proteins, plasmids, AMR, P4 satellites, and the newly discovered Obelisk RNA elements.

All Logan data is freely-available (cc0) right now. We show how Logan-Search (www.logan-search.org) can be used to uncover viral reactivation (HHV-6) in cell therapy products (TIL and CAR-T).

Logan rapidly accesses the tapestry of Life’s genetic diversity and can help solve global issues.
To tackle the microplastic crisis, we searched Logan for new versions of the 213 known plastic-degrading enzymes. We identified 200+ million homologs 🤯, including new high-efficiency enzymes 🥤🔥

Logan enables minute-scale k-mer search, and hour-scale deep homology protein alignment search, across 100+ Billion proteins.
www.logan-search.org

One year after our initial preprint, we're excited to post a major update to Logan.
At its heart, Logan is the assembly of 27 million samples (50 Pbp) using a 6-day cloud-compute peaking at 2.2M vCPUs. This compresses the SRA 140x compared to raw FASTQs.
github.com/IndexThePlan...

🌎👩🔬 For 15+ years biology has accumulated petabytes (million gigabytes) of🧬DNA sequencing data🧬 from the far reaches of our planet.🦠🍄🌵
Logan now democratizes efficient access to the world’s most comprehensive genetics dataset. Free and open.
doi.org/10.1101/2024...


Congratulations to Rayan Chiki, (Institut Pasteur) head of the “Sequence Bioinformatics” unit, for securing the ERC Proof of Concept 2025 for his project ENZYMINER! 👏
@rayan.chiki.bsky.social
#Bioinformatics
thanks Niema!
thanks Ben!!
merci Sophie!
yes😅
Slides from my talk (with @kamilsjaron.bsky.social) on an history of k-mers in bioinformatics: rayan.chikhi.name/pdf/2025-kme...

🧬 Excited to share our latest work, MUSET 🌭, a new tool for creating abundance unitig matrices from sequencing data. It was published yesterday in Oxford Bioinformatics if you want to have a look👀 :
academic.oup.com/bioinformati...
Let's break it down:

For more context: Logan is a collection of all public sequencing data (until end of 2023) assembled into contigs. It is freely hosted on the cloud, and contains hundreds of terabytes of valuable genomic data: github.com/IndexThePlan...
We have updated all Logan contigs (now at version 1.1)! Contiguity has been much improved (2x) and a duplicated k-mers bug has been fixed. More information and changelog here: github.com/IndexThePlan...


🚨 Keynotes at RECOMB-seq 2025! 🚨
🌟 Alicia Oshlack – computational transcriptomics
@aliciao.bsky.social
🌟 Rayan Chikhi – sequencing data structures
@rayanchikhi.bsky.social
🗓️ Dates: April 24–25, 2025
📍 Seoul, South Korea
recomb-seq.github.io/speakers/

Do you want to learn systematic ways in which you can revise your research papers? I've posted a short collection of 4 lectures youtube.com/playlist?lis... 1/n
Ty Rob!
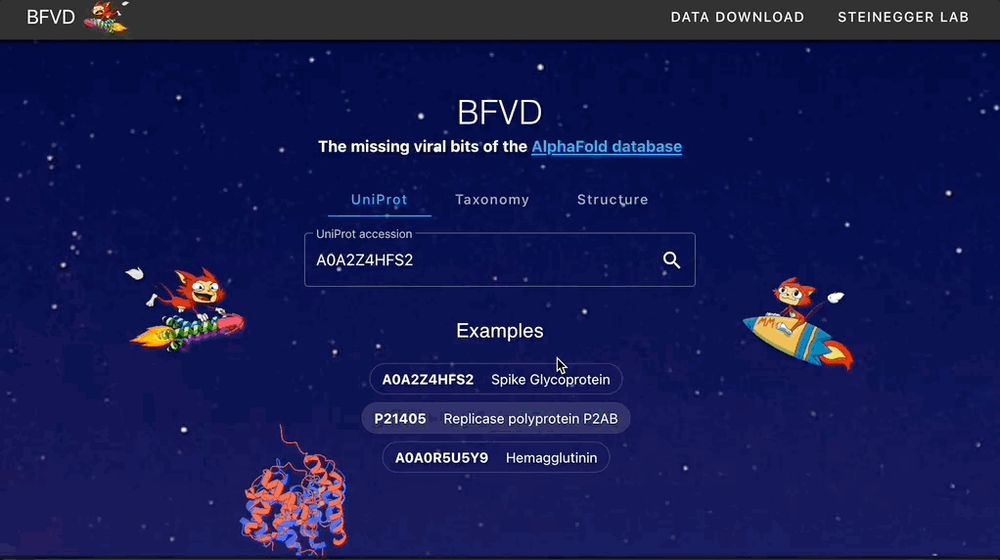
Our Big Fantastic Virus Database (BFVD) is now published NAR! It contains protein structure predictions of major viral clades, enhanced by petabase-scale homology search and it's explorable on the web.
🌐 bfvd.foldseek.com
💾 bfvd.steineggerlab.workers.dev
📄 academic.oup.com/nar/advance-...