
Interesting physics punctuated by incredible videos!
03.03.2026 22:30
👍 7
🔁 1
💬 0
📌 0
Interesting physics punctuated by incredible videos!

Differences between species should be treated as informative constraints that refine theory, not as inconsistencies to be explained away, writes @suthanalab.bsky.social.
#neuroskyence
www.thetransmitter.org/animal-model...
Can we predict a thought before it happens?
To know what one neuron will do next, you have to know what the entire brain is doing right now.
In our latest @kempnerinstitute.bsky.social Deeper Learning blog, @duranrin.bsky.social introduces POCO, a tool paving the way for adaptive neurotechnology.
Same task, different strategy ↔️
Why do identical neural network models develop separate internal approaches to solve the same problem?
@annhuang42.bsky.social explores the factors driving variability in task-trained networks in our latest @kempnerinstitute.bsky.social Deeper Learning blog.
Enormous thanks to John Vastola for leading this work, @gershbrain.bsky.social for the collaboration & @harvardmed.bsky.social, @kempnerinstitute.bsky.social for their support ✨
Read the full paper here & let us know what you think: openreview.net/forum?id=oMi...
(6/6)
For any ML folks out there, our framework helps clarify why certain algorithms work under specific assumptions. It can justify design choices & suggest new directions, but empirical testing is still essential to validate what works in practice (5/6)
What does this mean for understanding real brains? 🧠
Neurons face very different constraints than AI, with limited information & noisy signals. Learning rules that look "messy" compared to AI models might actually be optimal within a biological system (4/6)

The answer depends on your constraints, like how far ahead you can plan, how much of the landscape you can see, and what kinds of moves you can make.
Our framework can derive the optimal strategy in each case. (3/6)

Standard learning methods only ask what the next best step is & take it. We reframed learning as navigating a landscape, where the goal is to find the best path over many steps.
This lets us ask a new question: what's the optimal way to navigate? 🗺️ (2/6)

New paper for #neurips2025!
AI models adjust millions of internal settings to get better at a task. But how are these adjustments determined? For decades, we've mostly figured this out through trial & error.
We took a different approach...🧵 (1/6)
🔗 openreview.net/forum?id=oMi...

Conference poster schedule

Workshop poster schedule
Celebrating the Rajan Lab’s papers at #NeurIPS2025! Stop by to chat with these talented students and postdocs 🎉

To identify the most transformative tools and technologies in the past five years, @thetransmitter.bsky.social surveyed readers and contributors and worked with a market-research firm to interview neuroscientists around the world. See what they had to say: bit.ly/3LYTNoB
#StateOfNeuroscience

📍Excited to share that our paper was selected as a Spotlight at #NeurIPS2025!
arxiv.org/pdf/2410.03972
It started from a question I kept running into:
When do RNNs trained on the same task converge/diverge in their solutions?
🧵⬇️
Awesome work co-led by my student @annhuang42.bsky.social and @neurostrow.bsky.social on disentangling, then comparing recurrent and externally driven dynamics!
Look out for more incredible work from @annhuang42.bsky.social coming up at NeurIPS 👀

Congrats to Ann Huang for an excellent presentation at last week's @kempnerinstitute.bsky.social all-hands! 👏
Ann shared exciting updates about our InputDSA tool - more to come soon. Thrilled she had the chance to present to our engaged and supportive community.

(8/8) To apply POCO to your own work, find our open source code on github below 👇
github.com/yuvenduan/POCO

(7/8) Thanks to @deisseroth.bsky.social, @mishaahrens.bsky.social & Chris Harvey for their contributions, and to @kempnerinstitute.bsky.social & @harvardmed.bsky.social for supporting computational neuroscience research.
Read the paper here: arxiv.org/abs/2506.14957

(6/8) Combined with its prediction speed and steady improvement from longer recordings/more sessions, POCO shows enormous potential for usage in larger brains & real-time neurotechnologies like “neuro-foundation models” for brain-computer interfaces (BCI).
(5/8) Other time-series forecasting models perform well on synthetic/simulated data 🤖
POCO dominates in context-dense predictions based on REAL neural data 🧠

(4/8) Beyond neural predictions, POCO's learned unit embeddings independently reproduce brain region clustering without any anatomical labels.
That means at single-cell resolution across entire brains, POCO mimics biological organization purely from neural activity patterns ✨
(3/8) POCO forecasts how the brain will behave up to ~15 seconds into the future across behavioral data & species 🔮
After pre-training, POCO’s speed & flexibility allow it to adapt to new recordings with minimal fine-tuning, opening the door for real-time applications.

(2/8) POCO was trained on spontaneous & task-specific behavior data from zebrafish, mice, & C. elegans. It combines a local forecaster with a population encoder capturing brain-wide patterns, so we track each neuron individually AND how the whole brain affects each cell 🧠

(1/8) New paper from our team!
Yu Duan & Hamza Chaudhry introduce POCO, a tool for predicting brain activity at the cellular & network level during spontaneous behavior.
Find out how we built POCO & how it changes neurobehavioral research 👇
arxiv.org/abs/2506.14957




Thanks for having me at @camp_course and the @iitmadras Brain Center during my visit to India this summer!🥭
It was lovely to be back home, and a pleasure to work with the young scientists there who are finding their path in computational neuroscience 🧠

Brilliant piece by @mattperich.bsky.social on neural manifolds 🌟
His essay in @thetransmitter.bsky.social shows how this view changes the game in computational neuroscience, reproducing behavioral flexibility within finite neural constraints 🧠
www.thetransmitter.org/neural-dynam...

Check out @jordancollver.bsky.social’s great illustration of modular RNNs training to work like a bio-brain🦾🧠
Thanks to Crearte for featuring our collaboration!
www.instagram.com/crearte.ca/p...
(7/7) Congrats to Riley & Ryan on this work. Also huge thanks to collaborators Felix Berg, @raymondrchua.bsky.social, John Vastola, @joshlunger.bsky.social, Billy Qian & everyone who helps us kick the tires.
(6/7) A 4096-unit agent that remembers, plans & navigates risks gives a “window-sized” brain we can watch neuron-by-neuron. ForageWorld is a perfect sandbox for testing cognitive map theories & offers a blueprint for ultra-efficient autonomous AI systems in a naturalistic world.
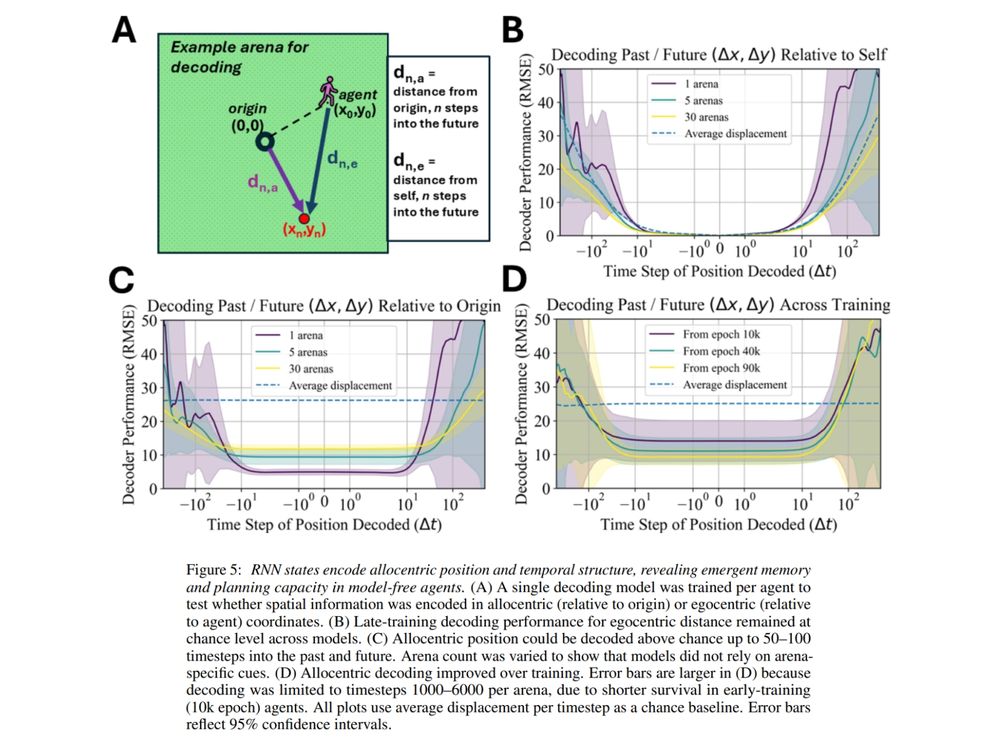
(5/7) Analyzing the trained agent reveals an interpretable neural GPS: past & future positions can be linearly decoded over long horizons from the agent’s ‘neural’ activity, and a lightweight “predict-its-own-position” signal sharpens its compass even further.
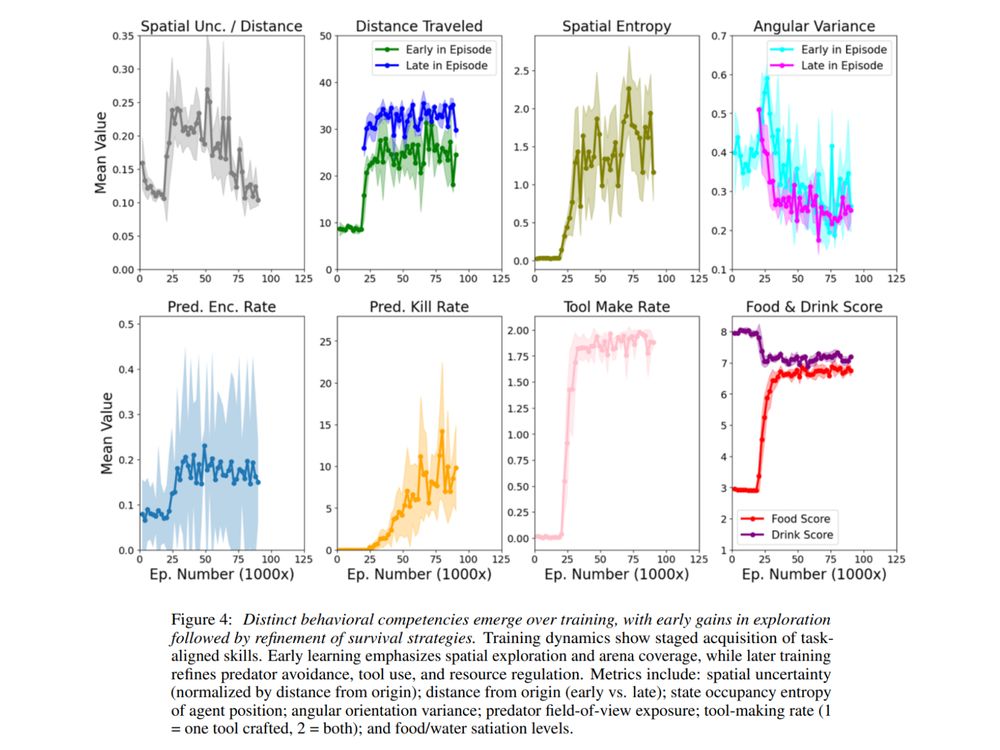
(4/7) What we see is planning & recall over hundreds of timesteps!
After a quick wander, the agent switches from exploring to visiting patches from memory: revisiting food not seen for over 500-1000 steps, skirting predator zones & timing resource visits.