
Melody Huang (Yale) | Applied Statistics Workshop Gov 3009
Breadcrumbs
Weds at 12:00 ET: #Yale assistant professor @melodyyhuang.bsky.social presents "Relative Bias Under Imperfect Identification in Observational #CausalInference" at this week's #AppliedStatistics workshop. #politicalscience #statistics
appliedstatsworkshopgov3009.hsites.harvard.edu/event/melody...
04.03.2026 14:12
👍 0
🔁 1
💬 0
📌 0
But have you seen Love Never Dies?? (It gets so much worse...)
24.02.2026 00:43
👍 0
🔁 0
💬 1
📌 0

Congrats to BART rider and Oakland legend Alysa Liu on winning a gold medal at the Olympics and making the Bay Area proud!
19.02.2026 22:21
👍 7606
🔁 1074
💬 46
📌 132
The “problem solving” approach and social science methodology – Cyrus Samii
I keep coming back to @cdsamii.bsky.social essay on the “problem-centered” over “puzzle-centered” research paradigm and I can’t help but feel like so many problems with social science methods boil down to this cyrussamii.com?p=3682
14.02.2026 20:02
👍 26
🔁 7
💬 1
📌 0
![Comic. Conjecture: It’s possible to construct a convincing proof without words, pictures, or content of any kind. Proof: [empty box] [caption] Proofs without words are cool, but we can go further.](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:cz73r7iyiqn26upot4jtjdhk/bafkreiaukmlmzx6xhbcjej4rq5axkf7a25sjywnvodd53dgnebmt4ver5a@jpeg)
Comic. Conjecture: It’s possible to construct a convincing proof without words, pictures, or content of any kind. Proof: [empty box] [caption] Proofs without words are cool, but we can go further.
Proof Without Content
xkcd.com/3201/
03.02.2026 20:56
👍 2647
🔁 295
💬 40
📌 25
A blog post giving a more thorough take on survey experiments and the credibility revolution: cyrussamii.com?p=4168
03.12.2025 17:23
👍 79
🔁 36
💬 6
📌 6
To me this is a depressing theme in modern academia.
There is so much work being produced, and so many competing demands on our time, that people rarely seem able to just closely read work and frankly say "yes, I believe this" or "no, I don't."
If we aren't doing this, what _are_ we doing?!
30.11.2025 10:57
👍 46
🔁 9
💬 1
📌 2

new paper by Sean Westwood:
With current technology, it is impossible to tell whether survey respondents are real or bots. Among other things, makes it easy for bad actors to manipulate outcomes. No good news here for the future of online-based survey research
18.11.2025 19:15
👍 777
🔁 390
💬 41
📌 126
Excellent report on experiences of @guidoimbens.bsky.social & Mary Wootters co-teaching "Causality, Decision Making, and Data Science" to undergrads at Stanford fall 2024: hdsr.mitpress.mit.edu/pub/uynpjlow... Course material here: stanford-causal-inference-class.github.io
03.11.2025 16:14
👍 7
🔁 3
💬 0
📌 0
Going to include this on my slides about partial identification
16.09.2025 19:39
👍 12
🔁 1
💬 0
📌 0
Population Studies Workshop
| Institution for Social and Policy Studies
The Yale Population Studies Workshop is live! Check out our fall lineup here: isps.yale.edu/population-s... Speakers span sociology, economics, medicine, and political science. Both Yale and non-Yale folks are welcome to sign up for the email listserv!
26.08.2025 15:46
👍 6
🔁 2
💬 0
📌 1
Could that be @melodyyhuang.bsky.social's new #rstats package for sensitivity analyses? 👀
22.08.2025 21:41
👍 7
🔁 2
💬 1
📌 0

Lots of different ways to do observational causal inference—IV, proximal inference, etc. What if you could compare those strategies more directly?
New preprint w/ @melodyyhuang.bsky.social tries to do just that. Here's one cool figure—we're able to visualize bias of 3 estimators on the same plot
01.08.2025 16:59
👍 22
🔁 7
💬 3
📌 1
We show that the act of choosing an identification strategy implicitly expresses a belief about the degree of violations that must be present in alternative identification strategies. (4/4)
01.08.2025 14:17
👍 0
🔁 0
💬 0
📌 0
To help compare the sensitivities across the different identification strategies, we propose a set of sensitivity tools and an augmented bias contour plot visualizes the relationship between these strategies. (3/n)
01.08.2025 14:17
👍 0
🔁 0
💬 2
📌 0
We develop bias expressions for IV and proximal inference that show how violations of their respective assumptions are actually *amplified* by any unmeasured confounding in the outcome variable. (2/n)
01.08.2025 14:17
👍 1
🔁 0
💬 1
📌 0
![4-panel comic. (1) [Person 1 with ponytail flanked by person with short hair and another person speaking into microphone at podium] PERSON 1: In the early 2010s, researchers found that many major scientific results couldn’t be reproduced. (2) PERSON 1: Over a decade into the replication crisis, we wanted to see if today’s studies have become more robust. (3) PERSON 1: Unfortunately, our replication analysis has found exactly the same problems that those 2010s researchers did. (4) [newspaper with image of speakers from previous panels] Headline: Replication Crisis Solved](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:cz73r7iyiqn26upot4jtjdhk/bafkreibwuu57ullc7vacjyno6c5z3gtyakkg2qub6cn3dbbjdpn2kaowmi@jpeg)
4-panel comic. (1) [Person 1 with ponytail flanked by person with short hair and another person speaking into microphone at podium] PERSON 1: In the early 2010s, researchers found that many major scientific results couldn’t be reproduced. (2) PERSON 1: Over a decade into the replication crisis, we wanted to see if today’s studies have become more robust. (3) PERSON 1: Unfortunately, our replication analysis has found exactly the same problems that those 2010s researchers did. (4) [newspaper with image of speakers from previous panels] Headline: Replication Crisis Solved
Replication Crisis
xkcd.com/3117/
21.07.2025 23:54
👍 4878
🔁 659
💬 28
📌 31

I have a new R package, 'bases,' out on CRAN today!
'bases' provides a number of basis expansions that you can use inside any modeling formula. This means you can fit nonparametric regressions with lm() or glmnet() easily!
Bases includes random Fourier features, approximate BART, and more!
29.05.2025 21:28
👍 10
🔁 3
💬 1
📌 0
We are pleased to announce an experiment intended to stimulate academic discussion and exchange, centered on papers published in Econometrica 1/5
27.03.2025 12:36
👍 121
🔁 38
💬 2
📌 15
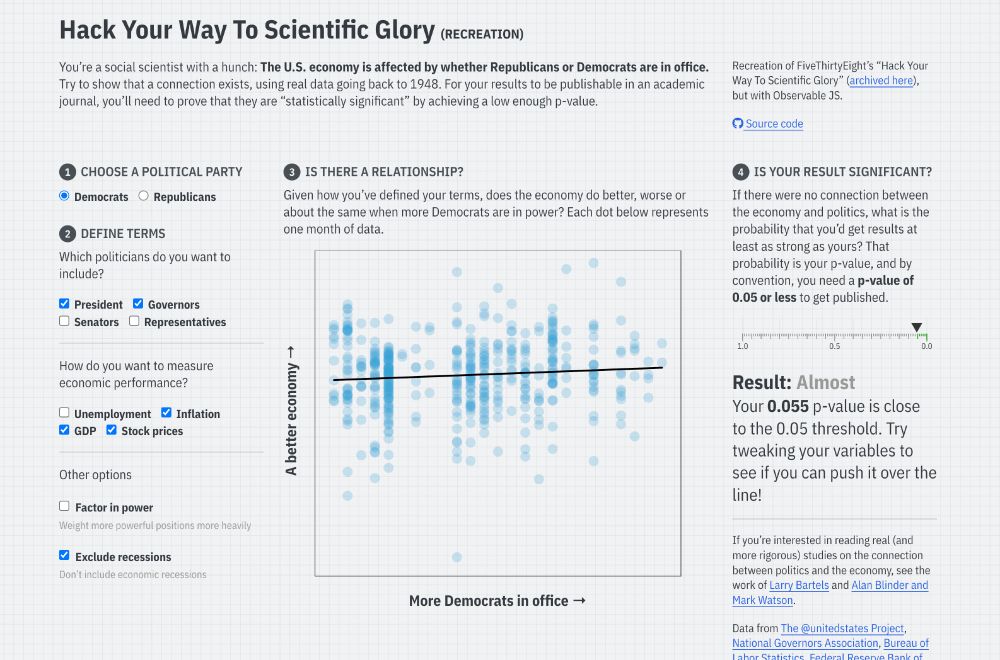
Screenshot of the linked Quarto website, with input checkboxes to change different conditions for a regression model that predicts economic performance based on US political party, with a reported p-value
I’ve long used FiveThirtyEight’s interactive “Hack Your Way To Scientific Glory” to illustrate the idea of p-hacking when I teach statistics. But ABC/Disney killed the site earlier this month :(
So I made my own with #rstats and Observable and #QuartoPub ! stats.andrewheiss.com/hack-your-way/
20.03.2025 18:30
👍 1464
🔁 437
💬 57
📌 29
*Please repost* @sjgreenwood.bsky.social and I just launched a new personalized feed (*please pin*) that we hope will become a "must use" for #academicsky. The feed shows posts about papers filtered by *your* follower network. It's become my default Bluesky experience bsky.app/profile/pape...
10.03.2025 18:14
👍 522
🔁 296
💬 23
📌 83
Does drinking this much coffee lower the risk of omitted variable bias?
11.03.2025 14:57
👍 249
🔁 33
💬 10
📌 2
Congratulations Anton!!!
17.12.2024 16:45
👍 1
🔁 0
💬 0
📌 0
Congratulations Guilherme!
17.12.2024 16:11
👍 1
🔁 0
💬 1
📌 0
Key features:
- Closed-form solution: The robust CATE is an interpretable weighted average of site-specific CATE models.
- Flexibility: Allows the use of off-the-shelf single-site CATE estimation methods.
- Privacy-preserving: Avoids sharing individual-level data across sites. (4/n)
17.12.2024 16:11
👍 0
🔁 0
💬 0
📌 0
We propose a minimax-regret framework for generalizing CATEs (conditional average treatment effects) across multisite data. We propose minimizing the worst-case regret over a class of target populations whose CATE can be represented as convex combinations of site-specific CATEs. (3/n)
17.12.2024 16:11
👍 0
🔁 0
💬 1
📌 0
Researchers often want to estimate HTEs that are consistent across different populations & contexts. When we have multiple source sites, we run into challenges:
(1) Site-specific models lack external validity.
(2) Pooled models risk bias if site heterogeneity is ignored. (2/n)
17.12.2024 16:11
👍 0
🔁 0
💬 1
📌 0



