Thanks to my amazing coauthors
@markar.bsky.social, Destiny Akinode, @kthai1618.bsky.social, Bradley Emi, Max Spero and @miyyer.bsky.social and the support of UMD Clip lab and Pangram Labs
22.10.2025 15:24
👍 1
🔁 0
💬 0
📌 0
We will be continuously monitoring American news to keep up with how AI use changes over time. Follow along at 🌐 ainewsaudit.github.io
22.10.2025 15:24
👍 2
🔁 1
💬 1
📌 1
AI has been creeping into the news all of us read, often without any disclosure. We call for clearly defined standards for U.S. newsrooms:
1️⃣ Clearly define what counts as acceptable use of AI and publish these standards openly
2️⃣ Require AI-use attestations for all writers
22.10.2025 15:24
👍 15
🔁 4
💬 1
📌 0
Many AI-written stories still contain authentic quotes. We hypothesize that people often use AI for editing or expanding on their human-written work. But with no disclosure, there's no way to tell for sure.
22.10.2025 15:24
👍 2
🔁 0
💬 1
📌 0

We also track how AI adoption has evolved over time:
Among 10 veteran reporters we followed longitudinally, AI use rose from 0% pre-ChatGPT (2022) to >40% in 2025.
22.10.2025 15:24
👍 0
🔁 0
💬 1
📌 0

AI is disproportionately affecting news written in languages other than English. Roughly ~8% of English news is AI-generated, compared to 33% of non-English languages (primarily Spanish). Without disclosure, we cannot be sure whether AI is translating stories or writing them.
22.10.2025 15:24
👍 0
🔁 0
💬 1
📌 0

In NYT, WaPo & WSJ, opinion sections show 6.4× higher AI use than other sections, rising ~25× since 2022 (from ~0% → ~4%).
AI use is concentrated among prominent guest authors: politicians, CEOs, and scientists.
22.10.2025 15:24
👍 4
🔁 2
💬 1
📌 2
Despite widespread use, transparency is basically nonexistent.
Out of 100 AI-flagged articles we manually annotated, only 5 disclosed that AI was used and over 90% of outlets have no public AI policy.
22.10.2025 15:24
👍 3
🔁 0
💬 1
📌 0

AI use isn’t evenly distributed:
🗞️ Far higher in small local papers than national outlets
🌎 Especially common in Mid-Atlantic & Southern states
🏢 Largely Driven by ownership groups (e.g. Boone Newsmedia & Advance Publications)
🧭 Most concentrated in weather, tech, and health
22.10.2025 15:24
👍 3
🔁 4
💬 1
📌 0

Pangram Labs AI Detection
The most accurate technology to detect AI-generated content. Detects ChatGPT, Gemini, Meta AI, Claude, and more. Supports 20+ languages with 99.98%+ accuracy.
We detect AI using Pangram, a model with a reported false positive rate of 0.001% on news text. We find that 5.2% of recent news Is completely AI-generated, with another 3.9% partially AI-generated. www.pangram.com/
22.10.2025 15:24
👍 2
🔁 1
💬 1
📌 0

AI is already at work in American newsrooms.
We examine 186k articles published this summer and find that ~9% are either fully or partially AI-generated, usually without readers having any idea.
Here's what we learned about how AI is influencing local and national journalism:
22.10.2025 15:24
👍 55
🔁 29
💬 5
📌 2

🤔 What if you gave an LLM thousands of random human-written paragraphs and told it to write something new -- while copying 90% of its output from those texts?
🧟 You get what we call a Frankentext!
💡 Frankentexts are surprisingly coherent and tough for AI detectors to flag.
03.06.2025 15:09
👍 34
🔁 8
💬 1
📌 1
International students will stop coming to American universities if their visas are going to be at risk. This will make our intellectual community poorer and also make tuition more expensive for domestic students.
08.04.2025 01:52
👍 595
🔁 165
💬 7
📌 16
There is a quasi-religion in Silicon Valley that views AI as godlike. This faith has always been parallel to Evangelical Christianity: salvation (transhumanism), the rapture (the technological singularity), and demons (Roko's Basilisk)
Lately the AI faith has fully fused with Christian Nationalism.
21.03.2025 22:51
👍 5985
🔁 1422
💬 101
📌 257

Introducing 🐻 BEARCUBS 🐻, a “small but mighty” dataset of 111 QA pairs designed to assess computer-using web agents in multimodal interactions on the live web!
✅ Humans achieve 85% accuracy
❌ OpenAI Operator: 24%
❌ Anthropic Computer Use: 14%
❌ Convergence AI Proxy: 13%
12.03.2025 14:00
👍 11
🔁 5
💬 1
📌 3

Is the needle-in-a-haystack test still meaningful given the giant green heatmaps in modern LLM papers?
We create ONERULER 💍, a multilingual long-context benchmark that allows for nonexistent needles. Turns out NIAH isn't so easy after all!
Our analysis across 26 languages 🧵👇
05.03.2025 17:06
👍 14
🔁 5
💬 1
📌 3
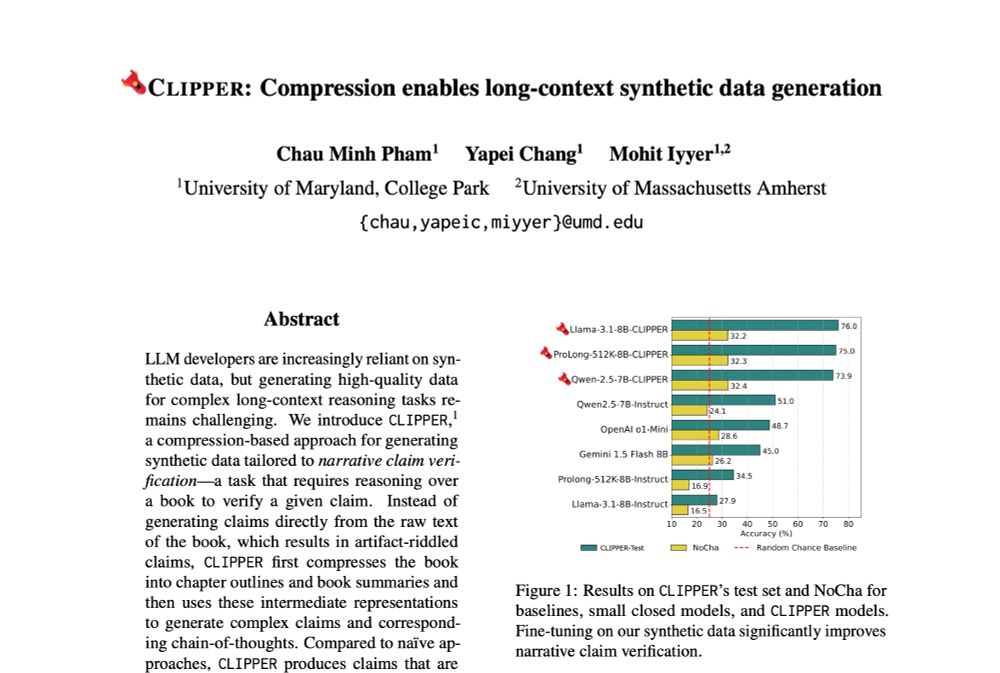
⚠️Current methods for generating instruction-following data fall short for long-range reasoning tasks like narrative claim verification.
We present CLIPPER ✂️, a compression-based pipeline that produces grounded instructions for ~$0.5 each, 34x cheaper than human annotations.
21.02.2025 16:25
👍 21
🔁 8
💬 1
📌 2
Also, the non experts have a range of LLM usage. Having a writing background is key, and a fact many are missing.
29.01.2025 12:39
👍 1
🔁 0
💬 0
📌 0
Hi Shane. We originally used 5 people, only 1 of whom could detect AI-generated text. I then searched out people who I thought could be experts and they had to pass multiple rounds of testing to be included in the study. Details in appendix. Nonexpert performance is already widely known.
29.01.2025 12:39
👍 0
🔁 0
💬 0
📌 0
This is a great question - we didn’t dive deeper than choosing articles from American publications. There were a few mentions where experts mentioned this awkward phrasing and thought it could be a non-native speaker, but still knew it was a human!
29.01.2025 12:36
👍 1
🔁 0
💬 1
📌 0
It would be very interesting to see if every language had their own set of “AI vocab” words 🤣
29.01.2025 00:16
👍 0
🔁 0
💬 1
📌 0
I think importantly is user who do writing tasks like editing/publishing! It’s the mix of having great language skills and frequent usage. Alot of ppl who just use LLMs a lot are way worse detectors than they think they’ll be.
29.01.2025 00:15
👍 4
🔁 0
💬 0
📌 0

GitHub - jenna-russell/human_detectors
Contribute to jenna-russell/human_detectors development by creating an account on GitHub.
📎 Paper: arxiv.org/abs/2501.15654
👩💻 Code & Data: github.com/jenna-russe...
Thanks to my amazing coauthors @markar.bsky.social and @miyyer.bsky.social and the support of UMass NLP
28.01.2025 14:55
👍 9
🔁 0
💬 2
📌 0
We're releasing our dataset of articles and expert annotations! 📂✨
We hope this helps users of automatic detectors understand not just if a text is AI-generated, but why. 🤖📖
28.01.2025 14:55
👍 3
🔁 0
💬 1
📌 0
Can LLMs mimic human expert detectors? 🤔
We prompted LLMs to imitate our expert annotators. The results show promise, outperforming detectors like Binoculars and RADAR. 🚀 However, LLMs still fall short of matching our human experts and advanced detectors like Pangram. ⚖️👥
28.01.2025 14:55
👍 2
🔁 0
💬 1
📌 0

What they get wrong: ❌
Sometimes, humans get tripped up by:
📚 Common "AI vocab" words in human-written texts
✍️ Grammar mistakes they assume "AI wouldn’t make"
🌀🗣️ One expert was often fooled by o1's use of informal language - like slang, contractions, and colloquialisms.
28.01.2025 14:55
👍 7
🔁 2
💬 1
📌 0

What experts get right: ✅
They spot telltale signs of AI, like:
📚 "AI Vocab" (delve, crucial, vibrant ...)
🔄 Predictable sentence structure
🗨️ Quotes that feel too polished
For human-written content, they look for:
🎨 Creativity
🎭 Stylistic quirks
🌊 A natural & clear flow
28.01.2025 14:55
👍 13
🔁 3
💬 1
📌 0

Across GPT-4o, Claude, and o1 articles, experts correctly identified 99.3% of AI-generated content without misclassifying any human-written articles.🕵️♀️
Among automatic detectors, Pangram significantly outperformed the rest, missing only a few more texts than the experts. 🔍⚡
28.01.2025 14:55
👍 10
🔁 0
💬 1
📌 0


