
🎓 Hats off to the 2025 IICD graduates: Yining Ma Junze Huang Yichi Yang Ruilin Dai Boan Zhu Cameron Park @jlfan.bsky.social & Achille Nazaret!
Wishing you all the best in your next chapter — we’re proud of you! 💙 #Columbia2025
@bleilab.bsky.social @khanhndinh.bsky.social @elhamazizi.bsky.social
21.05.2025 13:19
👍 5
🔁 1
💬 0
📌 0

I received a review like this five years ago. It’s probably the right time now to share it with everyone who wrote or got random discouraging reviews from ICML/ACL.
28.03.2025 19:55
👍 65
🔁 5
💬 1
📌 3

First 11 chapters of RLHF Book have v0 draft done. Should be useful now.
Next:
* Crafting more blog content into future topics,
* DPO+ chapter,
* Meeting with publishers to get wheels turning on physical copies,
* Cleaning & cohesiveness
rlhfbook.com
26.02.2025 16:35
👍 48
🔁 9
💬 0
📌 0

🔥 Benchmark Alert! MotifBench sets a new standard for evaluating protein design methods in motif scaffolding.
Why does this matter? Reproducibility & fair comparison have been lacking—until now.
Paper: arxiv.org/abs/2502.12479 | Repo: github.com/blt2114/Moti...
A thread ⬇️
19.02.2025 20:49
👍 41
🔁 17
💬 1
📌 5

The HuggingFace/Nanotron team just shipped an entire pretraining textbook in interactive format. huggingface.co/spaces/nanot...
It’s not just a great pedagogic support, but many unprecedented data and experiments presented for the first time in a systematic way.
19.02.2025 19:12
👍 39
🔁 9
💬 0
📌 0

I just wanted to see what it looked like 😭
19.02.2025 02:26
👍 3
🔁 0
💬 0
📌 0
Good God, please. I just want some gradients that don't vanish 😭
17.02.2025 03:01
👍 4
🔁 0
💬 1
📌 0
I was hoping that recent events would lead to a mass exodus from X. Many have left, but most of the ML and LLM people have not.
I have lost a lot of respect for the ML community.
05.02.2025 05:58
👍 72
🔁 4
💬 9
📌 2
Now that bluesky has gifs (it didn't work?), I can share (again) my educational notebook on discrete flow matching (by Itai Gat et al.). Also please check the original article and official implementation by Meta!
🐍 github.com/gle-bellier/...
🐍 github.com/facebookrese...
📄 arxiv.org/abs/2407.15595
05.02.2025 16:54
👍 15
🔁 2
💬 1
📌 0

This is a scatterplot with the following key features:
Axes:
The x-axis represents "Interest in AI," with values ranging approximately from -2 to 2.
The y-axis represents "Willingness to Tolerate Closed, Autocratic Systems," also ranging from about -2 to 2.
Data Points:
Black dots dominate the plot, distributed across all four quadrants, indicating diverse positions on both variables.
A few red dots labeled "my peeps" are clustered in the bottom-right quadrant, signifying high interest in AI but low tolerance for closed, autocratic systems.
Blue Lines:
The plot includes horizontal and vertical blue lines at zero, dividing it into four quadrants for visual reference.
This visualization highlights a subset of individuals ("my peeps") who stand out from the majority based on their distinct combination of interest and values.
I have a sinking feeling that by 2029 I'm going to be faking a British accent so no one will think I was one of the *Americans* working on AI during the regime.
03.02.2025 01:24
👍 111
🔁 10
💬 11
📌 0
NGL, it's kind of surprising that more people haven't migrated here, especially given what Musk has been doing these days. I don't get it.
03.02.2025 02:58
👍 1
🔁 0
💬 0
📌 0

Since everyone wants to learn RL for language models now post DeepSeek, reminder that I've been working on this book quietly in the background for months.
Policy gradient chapter is coming together. Plugging away at the book every day now.
rlhfbook.com/c/11-policy-...
01.02.2025 22:05
👍 156
🔁 20
💬 2
📌 1
Please stop anthropomorphizing language models, it makes them feel really bad
29.01.2025 23:20
👍 70
🔁 2
💬 3
📌 0

From the fednews community on Reddit
Explore this post and more from the fednews community
This comments section is the first time I've felt even a shred of hope in eight days.
29.01.2025 05:41
👍 20421
🔁 3851
💬 574
📌 648
Nazi salutes and speaking at neo-Nazi rallies seems bad. There's history that we should learn from.
26.01.2025 00:42
👍 115
🔁 5
💬 3
📌 0
Something I really like about NLP research is that it makes everything super intuitive. This week I have been thinking about variational inference in NLP and a lot of the things that seemed to require mathematical intuition just become trivial when thinking about language. So cool:)
25.01.2025 21:52
👍 2
🔁 0
💬 0
📌 0
Tests!! :)
25.01.2025 19:50
👍 3
🔁 0
💬 0
📌 0
But the memory needed for the value function kills the ones that don't have good GPUs 😭
25.01.2025 15:36
👍 0
🔁 0
💬 0
📌 0
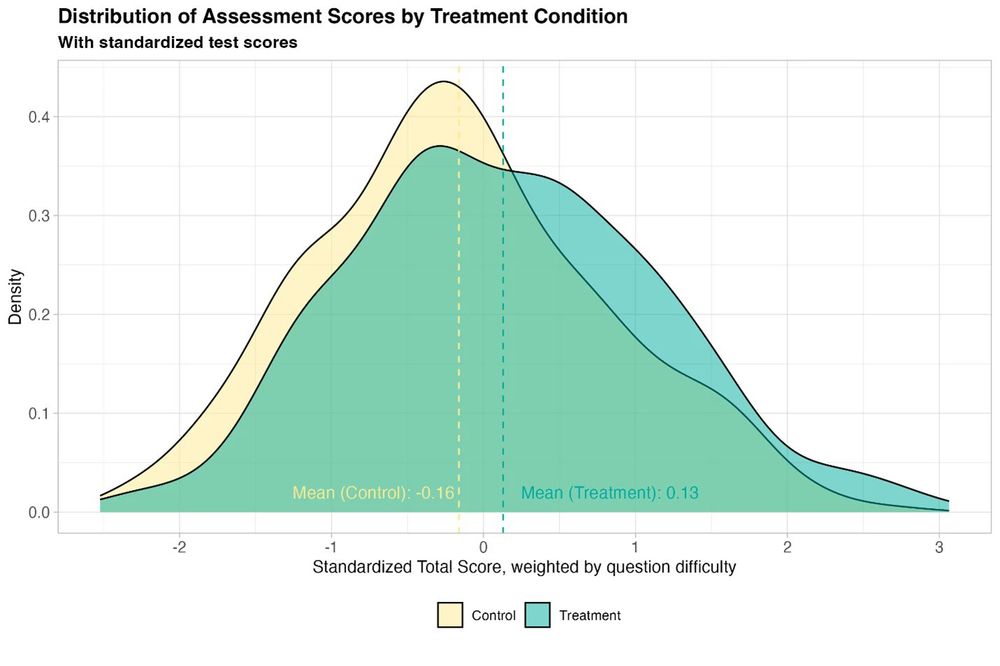
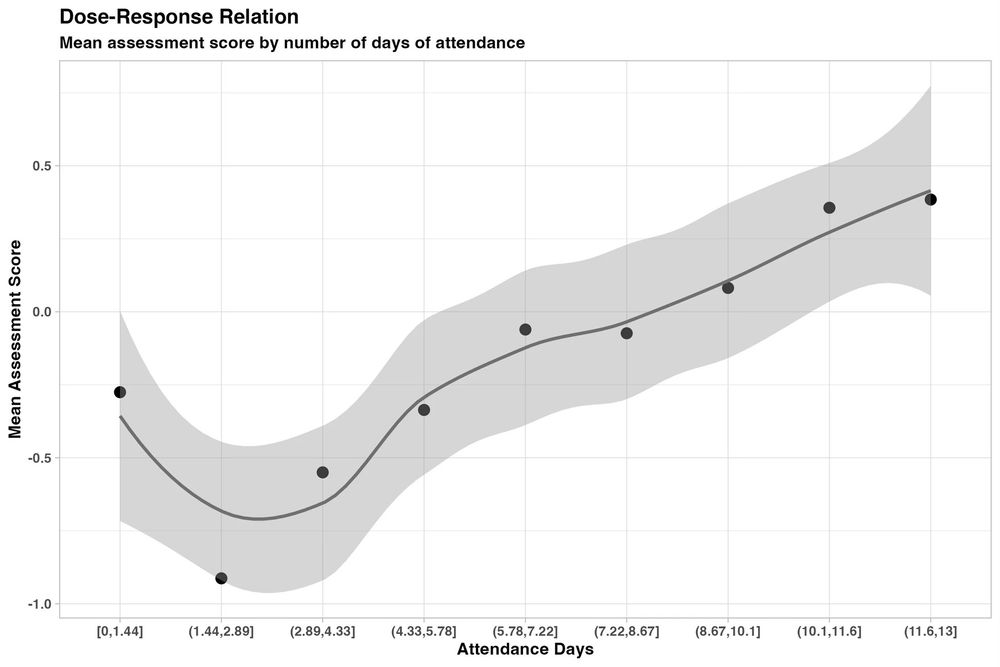
New randomized, controlled trial by the World Bank of students using GPT-4 as a tutor in Nigeria. Six weeks of after-school AI tutoring = 2 years of typical learning gains, outperforming 80% of other educational interventions.
And it helped all students, especially girls who were initially behind.
15.01.2025 20:58
👍 354
🔁 88
💬 15
📌 27
I mostly use copilot for writing code (as auto complete), gpt4-o for boiler plate, and o1 for serious debugging or boilerplate with some complexity or a lot of requirements. I also use o1 for quick but slightly involved experiments but not as often.
08.01.2025 19:36
👍 5
🔁 0
💬 0
📌 0
I use chatgpt over Google for a lot of things because it is really good at fuzzy queries + data aggregation from many sources. I feel that as long as you double check results it is much faster and convenient.
07.01.2025 00:40
👍 4
🔁 0
💬 0
📌 0
Does anyone have any good resources to learn about quantization? Any essential papers to read and resources about how to use/quantize models in practice are greatly appreciated!
28.12.2024 16:51
👍 3
🔁 0
💬 0
📌 0
That seems very reasonable no? I assumed the public set was used by most (almost all?) algorithms that have been benchmarked against the task. Isn't that the case? (legitimate question)
22.12.2024 00:41
👍 4
🔁 0
💬 0
📌 0
1-> 2 -> 3 -> 3.5 -> 4 -> 4o -> o1 -> o3
I guess we need AGI just to figure out how to name things
20.12.2024 19:17
👍 71
🔁 6
💬 7
📌 0
If you are into ML theory (RL or not) with a proven track record, and you are interested in an industry research position, PM me. Feel free to spread the word.
19.12.2024 00:55
👍 74
🔁 31
💬 2
📌 0
🧵 Excited to share #Echidna, a Bayesian framework for quantifying the impact of gene dosage on phenotypic plasticity: tinyurl.com/296kf7hf!
With @elhamazizi.bsky.social and @mingxz.bsky.social, we integrate scRNA-seq & WGS to uncover how CNAs drive tumor evolution and transcriptional variability.
18.12.2024 13:30
👍 15
🔁 6
💬 2
📌 2




