29.05.2025 12:59
👍 1
🔁 0
💬 0
📌 0
Yes! I tell my class that regression coefficients are the "unique" relationships of a variable. If variables are not "unique", there is less information available to make the SEs "smaller." It's always either multicollinearity or normality assumptions that you've got to disabuse students of!
30.04.2025 14:21
👍 2
🔁 0
💬 0
📌 0

Parameters aren't real.
29.04.2025 13:16
👍 37
🔁 5
💬 2
📌 0
Wait, you're telling me that a study in 20 children with ADHD showing an increased correlation between 2 arbitrarily defined brain regions doesn't represent a paradigm shift in how we could treat ADHD with respect to possible targeted pharmaceuticals?
17.04.2025 15:16
👍 2
🔁 0
💬 0
📌 0

Gif of police officer, dramatic high contrast lighting, looking confused and asking, "Are we the baddies?"
The one simple trick to avoid > 75% of bad uses of AI that AI ethicists don't want you to know!
Read a science fiction book and if your goal aligns with the bad guys in that book don't do it.
-- Credit @stellaathena.bsky.social on the Bad Site.
09.04.2025 17:15
👍 69
🔁 18
💬 5
📌 2
I mean, why do journals give due dates on RRs if not to encourage us to submit at the very last second?
08.04.2025 14:59
👍 1
🔁 0
💬 0
📌 0
Me, moments before I unknowingly hit reply all on the faculty listserv: "We are currently clean on OPSEC"
26.03.2025 13:52
👍 3
🔁 0
💬 0
📌 0
Homebrew warlock patron "The P-factor" that lets you summon and bind fiends by drawing path diagrams for multi-level SEMs.
At level 17 you gain the ability to measure constructs ... without error!
25.03.2025 12:58
👍 4
🔁 0
💬 0
📌 0


In 2018 I gave a presentation on research data management to a group of graduate students. Not surprisingly, most of the problems and solutions I discussed 7 years ago, are still the same problems and solutions I see today. #databs
23.03.2025 15:44
👍 25
🔁 5
💬 0
📌 0

🧠 Applying to Psychology PhD programs? Join @UVA's virtual panel April 14 at 12:30PM! Current faculty & PhD students will share tips on choosing programs & creating competitive applications. All welcome, especially those from underrepresented groups. Register via QR code! #PsychPhD #GradSchool
18.03.2025 18:16
👍 5
🔁 5
💬 0
📌 0

IMPS 2025 - Psychometric Society
July 15-18, 2025 (Short Courses July 14)
This year I have the honour of serving the Psychometric Society as its President, and we have been working hard on the program for the International Meeting of the Psychometric Society (IMPS) psychometricsociety.org/imps-2025 You can submit an abstract here: imps2025.exordo.com
18.02.2025 10:31
👍 14
🔁 7
💬 1
📌 1
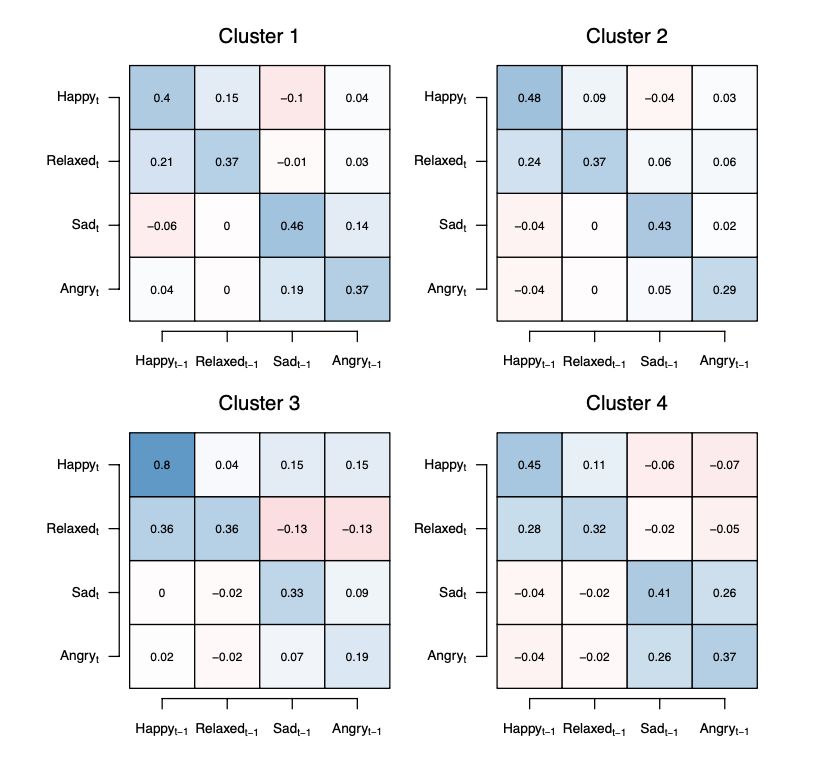
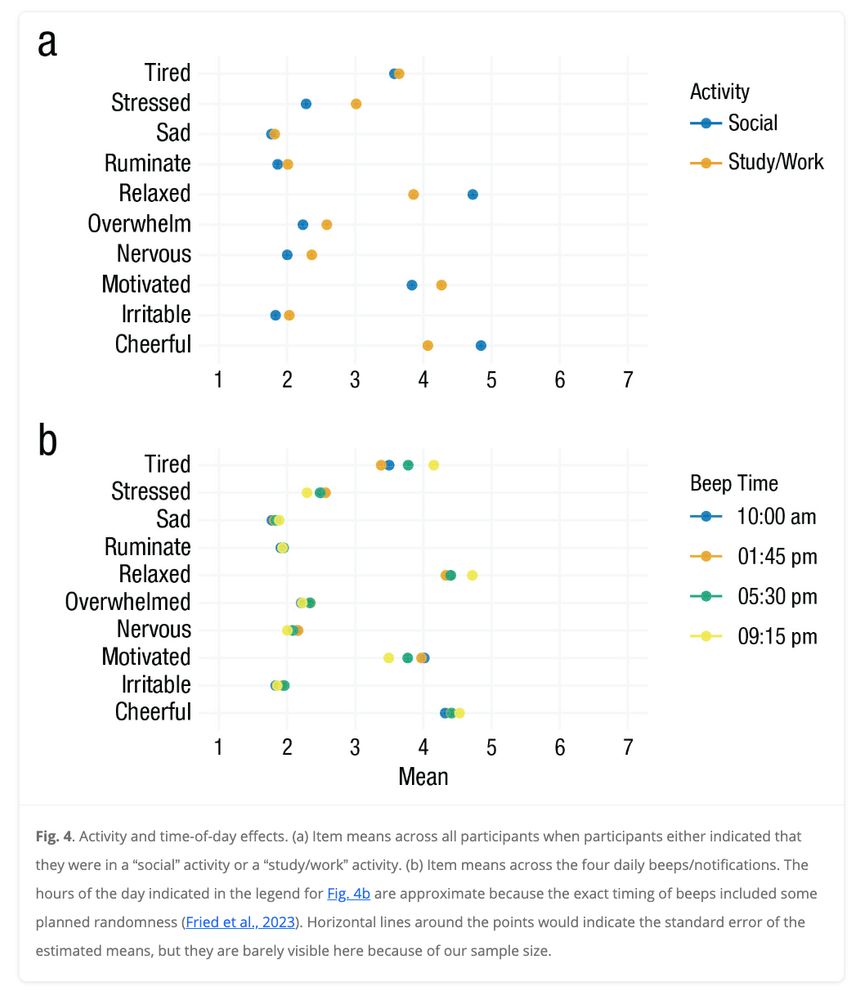
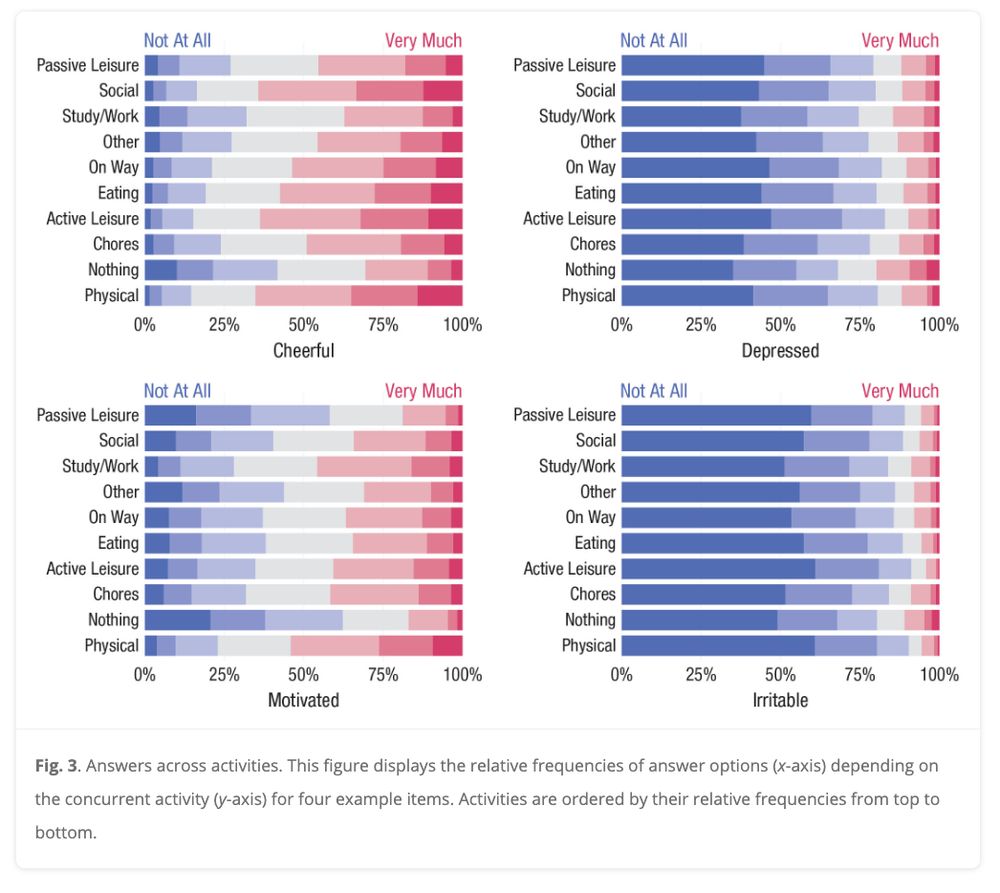
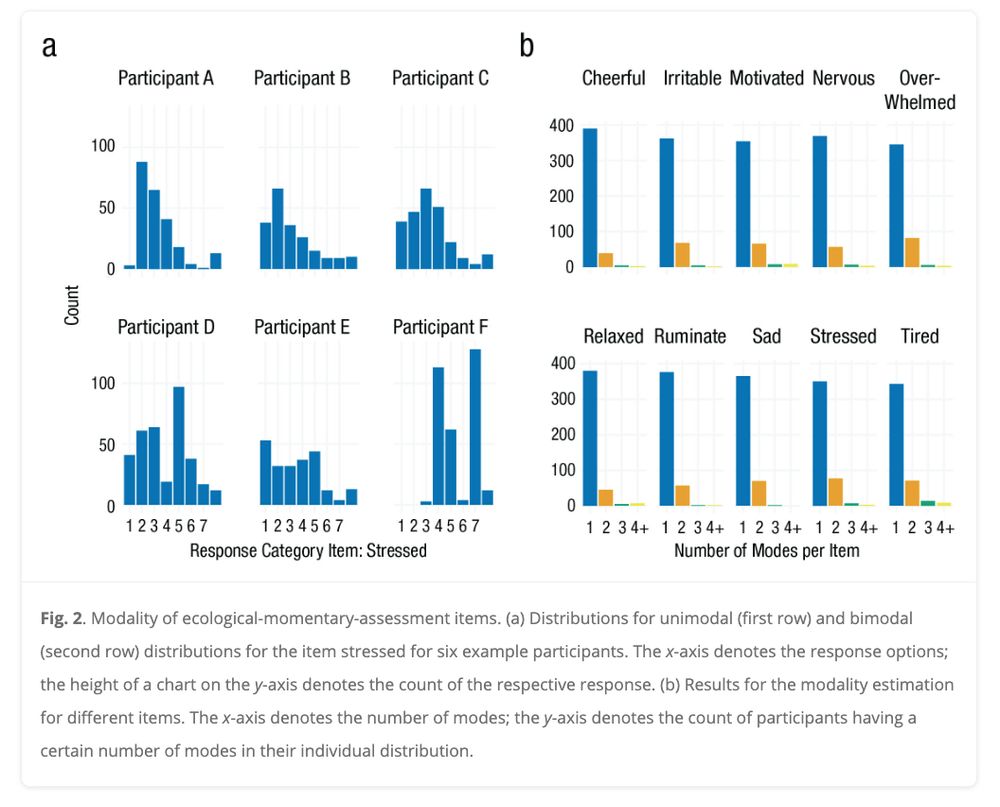
New preprint by Anja Ernst and me on Modeling Qualitative Between-Person Heterogeneity in Time-Series using Latent Class Vector Autoregressive Models (osf.io/preprints/ps...)
13.02.2025 15:06
👍 5
🔁 1
💬 1
📌 0
... to use human raters to reconcile any ambiguities. I think this is fascinating work, and a great example of how to use LLMs as a true tool for analyzing data (rather than just asking an LLM to analyze data). Joy is currently working on an extension to discover new topics, which is very exciting!
11.02.2025 21:05
👍 4
🔁 0
💬 0
📌 0
We found that ensembles of small LLMs tended to have reasonable (better than chance) performance at identifying topics. It wasn't perfect, but it is good enough to be a reasonable first pass through a large dataset. The idea is to first identify the cases that are easy to classify, then...
11.02.2025 21:05
👍 2
🔁 0
💬 1
📌 0
We compared the LLM topics to human raters topics. Now, importantly, Joy used an ensemble of LLMs (equivalent to having several human raters). Why? Well, we wanted for this method to be able to run locally, as there are a number of privacy issues with using consumer LLMs to analyze health data.
11.02.2025 21:05
👍 1
🔁 0
💬 1
📌 0
She applied this method to both a massive dataset of Reddit posts from eating disorder related forums, and a smaller dataset of free-text responses from patients with eating disorders (courtesy of @cherilev.bsky.social), and compared how well these LLMs could identify a prespecified set of topics.
11.02.2025 21:05
👍 2
🔁 0
💬 1
📌 0
So, Joy decided to use LLMs to query free-text data to extract "topics." For example, if a study collected responses regarding stressful events, then a topic might be a description like "work stressor" or "interpersonal stressor."
11.02.2025 21:05
👍 1
🔁 0
💬 1
📌 0
Enter LLMs! While I have a number of thoughts on LLMs that I won't get into here, for this project we conceptualized them as "tools that can comprehend free-text," with comprehension being akin to human reading comprehension (do LLMs comprehend? No, but they sure do seem like they do!)
11.02.2025 21:05
👍 1
🔁 0
💬 1
📌 0
Traditionally, this is done via teams of human raters. Researchers will put together groups of raters (usually grad students, possibly RAs) that will go through the free text responses and quantify them in some way. This takes an enormous amount of time and resources.
11.02.2025 21:05
👍 0
🔁 0
💬 1
📌 0
Free-text responses are a wonderful way of collecting nuanced information about any number of psychological phenomena, but the issue is, of course, that they are free-text responses. To perform quantitative analysis on them, you need to convert them into some set of numbers.
11.02.2025 21:05
👍 0
🔁 0
💬 1
📌 0
We originally thought about this project from an EMA perspective, trying to optimize for participant burden. So that’s where we are coming from!
08.02.2025 21:40
👍 0
🔁 0
💬 0
📌 0
To your second, I think this matters the most when only one/a couple questions per construct are asked. For a multi item scale, while I still want to see measurement errors of individual items, I don’t think the extra error induced by VAS would degrade wholistic scale performance.
08.02.2025 21:40
👍 0
🔁 0
💬 1
📌 0
Fortunately, it is an empirical question, and I would be happy with seeing that no, VAS doesn’t meaningfully degrade measurement! I just want to see the studies.
08.02.2025 21:40
👍 0
🔁 0
💬 1
📌 0
To your first question: yes, but different things matter more or less for measurement quality. For example, I wouldn’t think that a slight change in anchor language needs a revalidation (it could though!)
08.02.2025 21:40
👍 0
🔁 0
💬 1
📌 0
Found my new standard review comment
08.02.2025 16:54
👍 2
🔁 0
💬 1
📌 0