Finally, I want to thank the folks from HuggingFace for helping draft the official blog post (special shoutout to @clefourrier , @vanstriendaniel, @nathanhabib1011) and @Cohere_Labs for the research credits. :)
20.08.2025 20:40
👍 0
🔁 0
💬 0
📌 0
Evals are often the first step, we hope FilBench paves the way for language-specific adaptation especially for Philippine languages! I've written some of my thoughts here:
ljvmiranda921.github.io/projects/20...
20.08.2025 20:40
👍 0
🔁 0
💬 1
📌 0
Here's the link to the paper and leaderboard:
📜 Paper: arxiv.org/abs/2508.03523
📊 Leaderboard: ud-filipino-filbench-leaderboard.hf.space/
20.08.2025 20:40
👍 0
🔁 0
💬 1
📌 0
This collaboration is exciting, it felt like assembling the Avengers of Filipino NLP. @acocodes and Conner are great collaborators, and I was happy to team-up with @jcblaisecruz and @josephimperial_, who are working on Filipino NLP for longer than I did!
20.08.2025 20:40
👍 0
🔁 0
💬 1
📌 0

🇵🇭 FilBench - Can LLMs Understand and Generate Filipino?
🇵🇭 One of my research interests is improving the state of Filipino NLP
Happy to share that we're taking a major step towards this by introducing FilBench, an LLM benchmark for Filipino!
Also accepted at EMNLP Main! 🎉
Learn more:
huggingface.co/blog/filbench
20.08.2025 20:40
👍 4
🔁 0
💬 1
📌 0

Ai2 is excited to be at #ACL2025 in Vienna, Austria this week. Come say hello, meet the team, and chat about the future of NLP. See you there! 🤝📚
28.07.2025 17:00
👍 9
🔁 3
💬 0
📌 0

Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Samuel Cahyawijaya, Holy Lovenia, Joel Ruben Antony Moniz, Tack Hwa Wong, Mohammad Rifqi Farhansyah, Thant Thiri Maung, Frederikus Hudi, David Anugraha, Muhammad Ravi Shulthan Habibi, Muhammad Reza Qorib, Amit Agarwal, Joseph Marvin Imperial, Hitesh Laxmichand Patel, Vicky Feliren, Bahrul Ilmi Nasution, Manuel Antonio Rufino, Genta Indra Winata, Rian Adam Rajagede, Carlos Rafael Catalan, Mohamed Fazli Mohamed Imam, Priyaranjan Pattnayak, Salsabila Zahirah Pranida, Kevin Pratama, Yeshil Bangera, Adisai Na-Thalang, Patricia Nicole Monderin, Yueqi Song, Christian Simon, Lynnette Hui Xian Ng, Richardy Lobo Sapan, Taki Hasan Rafi, Bin Wang, Supryadi, Kanyakorn Veerakanjana, Piyalitt Ittichaiwong, Matthew Theodore Roque, Karissa Vincentio, Takdanai Kreangphet, Phakphum Artkaew, Kadek Hendrawan Palgunadi, Yanzhi Yu, Rochana Prih Hastuti, William Nixon, Mithil Bangera, Adrian Xuan Wei Lim, Aye Hninn Khine, Hanif Muhammad Zhafran, Teddy Ferdinan, Audra Aurora Izzani, Ayushman Singh, Evan Evan,
I was also part of a large-scale @seacrowd.bsky.social collaboration on building a vision-language dataset tailored for Southeast Asian Languages :) Also at ACL Main - aclanthology.org/2025.acl-lo...
July 29 Hall 4/5 10:30-12:00
#ACL2025 #ACL2025NLP
24.07.2025 12:56
👍 2
🔁 0
💬 0
📌 0

3️⃣ The UD-NewsCrawl Treebank: Reflections and Challenges from a Large-scale Tagalog Syntactic Annotation Project (Main) -
aclanthology.org/2025.acl-lo...
July 29 Hall 4/5 10:30-12:00
Collab with folks from UP Diliman
#ACL2025 #ACL2025NLP
24.07.2025 12:56
👍 0
🔁 0
💬 1
📌 0

2️⃣ M-RewardBench: Evaluating Reward Models in Multilingual Settings (Main) - aclanthology.org/2025.acl-lo...
July 28 Hall 4/5 11:00-12:30
Collab with folks from @cohereforai.bsky.social
#ACL2025 #ACL2025NLP
24.07.2025 12:56
👍 0
🔁 0
💬 1
📌 0

1️⃣ Hybrid Preferences: Learning to Route Instances for Human vs. AI Feedback (Main) - aclanthology.org/2025.acl-lo...
7/29 Hall 4/5 10:30-12:00
My project here at @ai2.bsky.social!
#ACL2025NLP
24.07.2025 12:56
👍 0
🔁 0
💬 1
📌 0

I'll be at @aclmeeting.bsky.social in Vienna! I'm going to present the ff first/co-first author works:
24.07.2025 12:56
👍 3
🔁 0
💬 1
📌 0


We’re thrilled that SEA-VL has been accepted to the ACL 2025 (Main)!
Thank you to everyone who contributed to this project 🥳
Paper: arxiv.org/abs/2503.07920
Project: seacrowd.github.io/seavl-launch/
#ACL2025NLP #SEACrowd #ForSEABySEA
16.05.2025 22:18
👍 2
🔁 4
💬 0
📌 0

Image illustrating that ALM can enable Ensembling, Transfer to Bytes, and general Cross-Tokenizer Distillation.
We created Approximate Likelihood Matching, a principled (and very effective) method for *cross-tokenizer distillation*!
With ALM, you can create ensembles of models from different families, convert existing subword-level models to byte-level and a bunch more🧵
02.04.2025 06:36
👍 25
🔁 14
💬 1
📌 0

🕵🏻💬 Introducing Feedback Forensics: a new tool to investigate pairwise preference data.
Feedback data is notoriously difficult to interpret and has many known issues – our app aims to help!
Try it at app.feedbackforensics.com
Three example use-cases 👇🧵
17.03.2025 18:12
👍 7
🔁 2
💬 1
📌 0

allenai/olmo-2-0325-32b-preference-mix · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
OLMo 2 0325 32B Preference Mixture: Solves AI alignment challenges through diverse preferences
- Combines 7 datasets
- Filters for instruction-following capability
- Balances on-policy and off-policy prompts
- Enabled successful DPO of OLMo-2-0325-32B model
huggingface.co/datasets/all...
13.03.2025 19:45
👍 6
🔁 2
💬 1
📌 0

The logo for Tülu 405B.
Here is Tülu 3 405B 🐫 our open-source post-training model that surpasses the performance of DeepSeek-V3! It demonstrates that our recipe, which includes RVLR scales to 405B - with performance on par with GPT-4o, & surpassing prior open-weight post-trained models of the same size including Llama 3.1.
30.01.2025 14:28
👍 92
🔁 20
💬 2
📌 8

kicking off 2025 with our OLMo 2 tech report while payin homage to the sequelest of sequels 🫡
🚗 2 OLMo 2 Furious 🔥 is everythin we learned since OLMo 1, with deep dives into:
🚖 stable pretrain recipe
🚔 lr anneal 🤝 data curricula 🤝 soups
🚘 tulu post-train recipe
🚜 compute infra setup
👇🧵
03.01.2025 16:02
👍 69
🔁 17
💬 2
📌 1
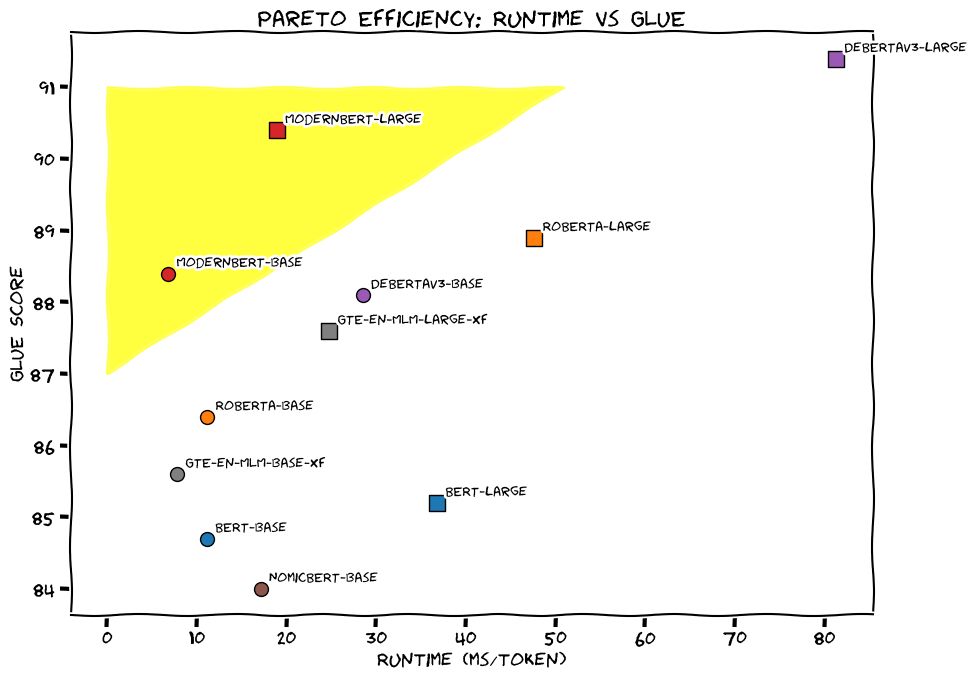
BERT is BACK! I joined a collaboration with AnswerAI and LightOn to bring you the next iteration of BERT.
Introducing ModernBERT: 16x larger sequence length, better downstream performance (classification, retrieval), the fastest & most memory efficient encoder on the market.
🧵
19.12.2024 16:41
👍 48
🔁 7
💬 1
📌 0

This is where the data to build AI comes from
New findings show how the sources of data are concentrating power in the hands of the most powerful tech companies.
New research reveals a worrying trend: AI's data practices risk concentrating power overwhelmingly in the hands of dominant technology companies. With analysis from
@shaynelongpre.bsky.social @sarahooker.bsky.social @smw.bsky.social @giadapistilli.com www.technologyreview.com/2024/12/18/1...
18.12.2024 17:34
👍 86
🔁 31
💬 2
📌 9
NeurIPS Tutorial Experimental Design and Analysis for AI ResearchersNeurIPS 2024
Stop by our #NeurIPS tutorial on Experimental Design & Analysis for AI Researchers! 📊
neurips.cc/virtual/2024/tutorial/99528
Are you an AI researcher interested in comparing models/methods? Then your conclusions rely on well-designed experiments. We'll cover best practices + case studies. 👇
07.12.2024 18:15
👍 86
🔁 13
💬 6
📌 1
NeurIPS Tutorial Opening the Language Model Pipeline: A Tutorial on Data Preparation, Model Training, and AdaptationNeurIPS 2024
the science of LMs should be fully open✨
today @akshitab.bsky.social @natolambert.bsky.social and I are giving our #neurips2024 tutorial on language model development.
everything from data, training, adaptation. published or not, no secrets 🫡
tues, 12/10, 9:30am PT ☕️
neurips.cc/virtual/2024...
10.12.2024 15:31
👍 147
🔁 17
💬 5
📌 3
Come chat with me at #NeurIPS2024 and learn about how to use Paloma to evaluate perplexity over hundreds of domains! ✨We have stickers too✨
10.12.2024 03:54
👍 21
🔁 4
💬 1
📌 0
Grassroots Science
A global initiative focused on developing state-of-the-art multilingual language models through grassroots efforts.
⭐️ We're going to launch Grassroots Science, a year-long ambitious, massive-scale, fully open-source initiative aimed at developing multilingual LLMs aligned to diverse and inclusive human preferences in Feb 2025.
🌐 Check our website: grassroots.science.
#NLProc #GrassrootsScience
09.12.2024 05:02
👍 7
🔁 5
💬 1
📌 3
Thank you @oxykodit.bsky.social !
04.12.2024 17:48
👍 1
🔁 0
💬 0
📌 0
Happy to share this and excited to bring this to the public! Nice collab with folks from the University of the Philippines (UP), @angelaquino_ph and Elsie Or, for this impactful work :) Hoping to have the official UD release next year as well.
04.12.2024 04:28
👍 1
🔁 0
💬 0
📌 0

UD-Filipino/UD_Tagalog-NewsCrawl · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
We're releasing the largest Universal Dependencies (UD) treebank for Tagalog, UD-NewsCrawl! This dataset has been a long time coming, but glad to see this through: 15k+ sentences versus the previous ~150 sents from older Tagalog treebanks.
🤗 : huggingface.co/datasets/UD-...
📝 : Paper soon!
04.12.2024 04:28
👍 14
🔁 2
💬 1
📌 1
Jonathan Berant (Tel Aviv University / Google) / Towards Robust Language Model Post-training
YouTube video by Yoav Artzi
I am seriously behind uploading Learning Machines videos, but I did want to get @jonathanberant.bsky.social's out sooner than later. It's not only a great talk, it also gives a remarkably broad overview and contextualization, so it's an excellent way to ramp up on post-training
youtu.be/2AthqCX3h8U
02.12.2024 03:45
👍 53
🔁 12
💬 1
📌 0



