
Ownership is a scam invented by big thing to sell more stuff.
24.01.2026 20:31
👍 1
🔁 0
💬 0
📌 0
Ownership is a scam invented by big thing to sell more stuff.
Severed hand?!? Just go to an embassy and do it there!
Phone, as well as email, are a way in which anyone in the world can get a piece of my attention whenever they want. As we are figuring out increasingly effective ways of monetizing attention, exploitation of this resource expands.
Oof
Be sure to make that point when the funding for the other stuff disappears all the same.



Happy Olmo day to all who celebrate.
Sorry to all who delayed releases today to get out of our way.
We're hiring.

Announcing Olmo 3, a leading fully open LM suite built for reasoning, chat, & tool use, and an open model flow—not just the final weights, but the entire training journey.
Best fully open 32B reasoning model & best 32B base model. 🧵


we released Olmo 3! lot of exciting stuff but wanna focus on:
🐟Olmo 3 32B Base, the best fully-open base model to-date, near Qwen 2.5 & Gemma 3 on diverse evals
🐠Olmo 3 32B Think, first fully-open reasoning model approaching Qwen 3 levels
🐡12 training datasets corresp to different staged training

I'm excited to announce my RLHF Book is now in pre-order for the @manning.com Early Access Program (MEAP), and for this milestone it's 50% off.
Excited to land in print in early 2026! Lots of improvements coming soon.
Thanks for the support!
hubs.la/Q03Tc37Q0
@ananyahjha93.bsky.social knows the pain. We once got reviews to a paper that said "Please do further experiments [which would cost $2M]", and _also_ a review that said "This work is too expensive to be relevant to anyone in the field.". In the same paper!

Incredible work by Apple's UX department, enabling three different corner radii at the same time 🙈

While reviewing for #CHI2026, I've noticed four new writing issues in #HCI papers, likely due to an increased use of #LLMs / #AI. I describe them here - and how to fix them: dbuschek.medium.com/when-llms-wr...
You presumably have something you want to run, and it doesn't run. Or it runs on CPU. Spin up a Claude Code console and tell it about the problem. Tell it the command line that produces the wrong result. It'll start suggesting ways of fixing your environment, down to modifying installed drivers.
Let Claude Code sort out your environment.
Are humans allowed to attend?
What field/area is like this now?

We’re releasing early pre-training checkpoints for OLMo-2-1B to help study how LLM capabilities emerge. They’re fine-grained snapshots intended for analysis, reproduction, and comparison. 🧵
Mein Dreijähriger: "Ich will den Lerns Geschichte Podcast hören!"
Was ist denn "Lerns Geschichte"?
Zwei Minuten später im Radio: "Lernen's a bissel @geschichte.fm, dann ..." 😲
Almost all post-training is "dusting off capable base models"
Unverified second hand information: In the US, all fish has to be flash-frozen before being served raw. In Canada, it does not.
I think for the moment we're competing on a different axis. They do quite well on impact per GPU hour. We do well on impact per person hour.
In ML, you can get surprisingly far without ever looking at your training data, and yet you'll always be limited. Thus, in ML, "look at the data" means, "Don't just stir the pot of linear algebra, find out what's really happening."
This project is a perfect model of an OLMo contribution. Well scoped, practical, sound theoretical underpinnings, and @lambdaviking.bsky.social
submitted the paper 24h before the deadline 😍.
It's integrated into the OLMo trainer here: github.com/allenai/OLMo...
Meanwhile, OLMo is now the citation for QK norm, which we definitely didn't invent? You win some, you lose some.
Finally, OLMo 1B. This is the most commonly requested OLMo feature l, and it's finally here.
After ICML, I decided all conferences should be in Vienna from now on.
I'm in Singapore for @iclr-conf.bsky.social ! Come check out our spotlight paper on the environmental impact of training OLMo (link in next tweet) during the Saturday morning poster session from 10-12:30 -- happy to chat about this or anything else! DMs should be open, email works too
Came across arxiv.org/pdf/2504.05058 today. What a cool example of work you can do when LLM training data is open!
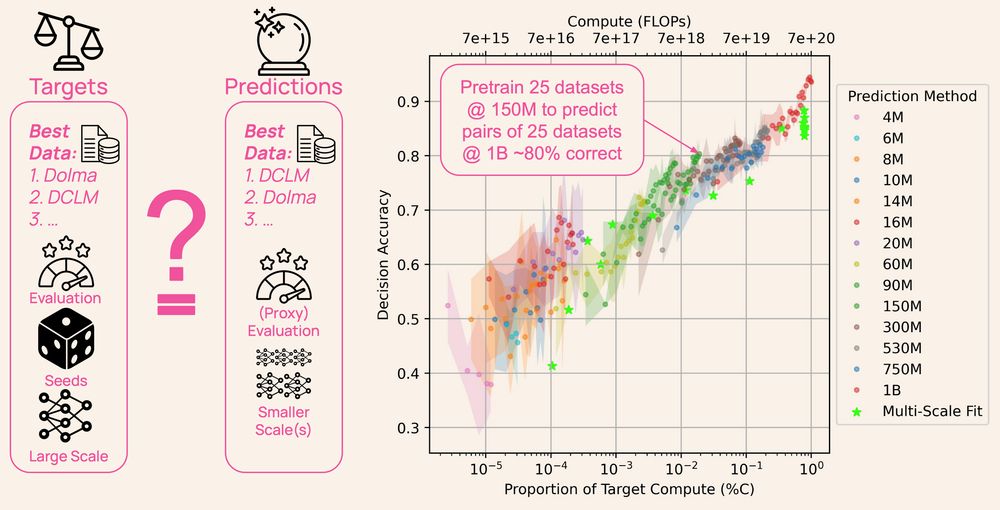
Plot shows the relationship between compute used to predict a ranking of datasets and how accurately that ranking reflects performance at the target (1B) scale of models pretrained from scratch on those datasets.
Ever wonder how LLM developers choose their pretraining data? It’s not guesswork— all AI labs create small-scale models as experiments, but the models and their data are rarely shared.
DataDecide opens up the process: 1,050 models, 30k checkpoints, 25 datasets & 10 benchmarks 🧵
Today we're unveiling OLMoTrace, a tool that enables everyone to understand the outputs of LLMs by connecting to their training data.
We do this on unprecedented scale and in real time: finding matching text between model outputs and 4 trillion training tokens within seconds. ✨