RLC2026 Call for Workshops!
We’re already live: openreview.net/group?id=rl-...
Here's the opportunity to help shape the conference & spotlight your own RL focus areas.
Call: rl-conference.cc/call_for_wor...
Deadline: Mar 12 (AoE)
And don't forget the awesome banquet :) www.cirquedusoleil.com/ludo
26.02.2026 20:30
👍 7
🔁 5
💬 0
📌 1
RLC'26 is inviting submissions!
Please mark your calendar, looking forward to all the new ideas.
Happy holidays!
@eugenevinitsky.bsky.social @audurand.bsky.social @schaul.bsky.social @glenberseth.bsky.social @sologen.bsky.social @pcastr.bsky.social @bradknox.bsky.social @cvoelcker.bsky.social
23.12.2025 23:10
👍 9
🔁 3
💬 0
📌 0
RLJ | RLC Call for Papers
Hi RL Enthusiasts!
RLC is coming to Montreal, Quebec, in the summer: Aug 16–19, 2026!
Call for Papers is up now:
Abstract: Mar 1 (AOE)
Submission: Mar 5 (AOE)
Excited to see what you’ve been up to - Submit your best work!
rl-conference.cc/callforpaper...
Please share widely!
23.12.2025 22:16
👍 61
🔁 28
💬 0
📌 8
Our paper, Towards Improving Reward Design in RL: A Reward Alignment Metric for RL Practitioners, won the Outstanding Paper Award on Emerging Topics in Reinforcement Learning this year at RLC! Congrats to 1st author @cmuslima.bsky.social!
Paper: sites.google.com/ualberta.ca/...
08.08.2025 00:21
👍 11
🔁 1
💬 0
📌 0
RLC Call for Workshops
Propose some socials for RLC! Research topics, affinity groups, niche interests, whatever comes to mind!
rl-conference.cc/call_for_soc...
25.06.2025 13:26
👍 11
🔁 8
💬 0
📌 2
Models of human preference for learning reward functions – Brad Knox, PhD
To do non-LLM RLHF research with real, non-author HUMAN data, last I checked there were few datasets available. Synthetic data is usually quite unrealistic, compromising your results (see bradknox.net/human-prefer...).
Our dataset (and code) with real humans: dataverse.tdl.org/dataset.xhtm...
30.04.2025 16:47
👍 2
🔁 0
💬 0
📌 0

Cursor + Claude pretending to do work.
Vibecoding apparently requires a magic touch I lack. In two attempts from scratch, Cursor AI + Claude 3.5 goes off the rails constantly and has eventually degenerated into non-functionality.
Degeneration #2: Claude is only pretending to run terminal commands and edit my code. 🤦
04.03.2025 18:01
👍 1
🔁 0
💬 2
📌 0
Giving such shorter-horizon feedback does tend to result in more varied reward rewards. And this variation bears resemblance to the meaning of the word dense, which I suspect is the origin of this misnomer. (4/n)
24.02.2025 17:27
👍 0
🔁 0
💬 0
📌 0
I find that what people really mean by "dense" is that so-called denser reward functions are giving feedback on *recent* state-action pairs, thus reducing the credit assignment problem (at some risk of misalignment). (3/n)
24.02.2025 17:27
👍 2
🔁 0
💬 2
📌 0
In standard RL, all reward functions give reward at every time step. A reward of 0 is informative, as is a reward of -1. So all reward functions are dense. (2/n)
24.02.2025 17:27
👍 1
🔁 0
💬 1
📌 0
Calling a reward function dense or sparse is a misnomer, AFAICT. (1/n)
24.02.2025 17:27
👍 2
🔁 0
💬 1
📌 0

RLC Keynote speakers: Leslie Kaelbling, Peter Dayan, Rich Sutton, Dale Schuurmans, Joelle Pineau, Michael Littman
Some extra motivation for those of you in RLC deadline mode: our line-up of keynote speakers -- as all accepted papers get a talk, they may attend yours!
@rl-conference.bsky.social
24.02.2025 11:16
👍 38
🔁 10
💬 0
📌 1

Announcement of Richard S. Sutton as RLC 2025 keynote speaker
Excited to announce the first RLC 2025 keynote speaker, a researcher who needs little introduction, whose textbook we've all read, and who keeps pushing the frontier on RL with human-level sample efficiency
08.01.2025 15:03
👍 52
🔁 4
💬 0
📌 0
Work led by Stephane Hatgis-Kessell, in collaboration with @reniebird.bsky.social, @scottniekum.bsky.social, Peter Stone, and me. Full paper: arxiv.org/pdf/2501.06416
14.01.2025 23:51
👍 0
🔁 0
💬 0
📌 0
Our findings suggest that human training and preference elicitation interfaces are essential tools for improving alignment in RLHF. The interventions of studies 2 and 3 can be applied for real-world application and suggest fundamentally new methods for model alignment (8/n)
14.01.2025 23:51
👍 1
🔁 0
💬 1
📌 0

Study 3: Simply changing the question asked during preference elicitation. (7/n)
14.01.2025 23:51
👍 2
🔁 0
💬 1
📌 0

Study 2: Training people to follow a specific preference model. (6/n)
14.01.2025 23:51
👍 2
🔁 0
💬 1
📌 0

Study 1 intervention: Show humans the quantities that underlie a preference model---normally unobservable information derived from the reward function. (5/n)
14.01.2025 23:51
👍 2
🔁 0
💬 1
📌 0
Every study involved a control and two intervention conditions that attempted to influence humans towards a preference model. For all 3 studies each intervention: (1) significantly influenced humans toward a preference model (2) led to learning more aligned reward functions (4/n)
14.01.2025 23:51
👍 1
🔁 0
💬 1
📌 0
We answer this question with 3 human studies. Without trying to alter the human's unobserved reward function, we change how humans use this reward function to generate preferences so that they better match the preference model assumed by an RLHF algorithm. (3/n)
14.01.2025 23:51
👍 1
🔁 0
💬 1
📌 0
RLHF algorithms typically require a model of how humans generate preferences. But a poor model of humans risks learning a poor approximation of the human’s unobservable reward function. We ask: *Can we influence humans to more closely conform to a desired preference model?* (2/n)
14.01.2025 23:51
👍 0
🔁 0
💬 1
📌 0

First page of the paper Influencing Humans to Conform to Preference Models for RLHF, by Hatgis-Kessell et al.
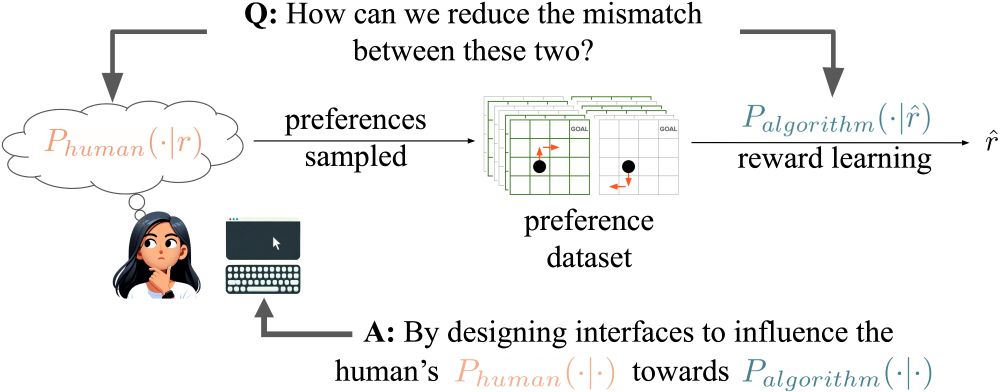
Our proposed method of influencing human preferences.
RLHF algorithms assume humans generate preferences according to normative models. We propose a new method for model alignment: influence humans to conform to these assumptions through interface design. Good news: it works!
#AI #MachineLearning #RLHF #Alignment (1/n)
14.01.2025 23:51
👍 7
🔁 3
💬 1
📌 0


