

Paper: arxiv.org/abs/2503.11751
It has been a very fun project. Thanks so much to all my collaborators Michi, Andrew, Yoon, Asli, and Marjan!
18.03.2025 16:01
👍 0
🔁 0
💬 0
📌 0
Paper: arxiv.org/abs/2503.11751
It has been a very fun project. Thanks so much to all my collaborators Michi, Andrew, Yoon, Asli, and Marjan!

💡A simple method improves robustness: including an aux loss that encourages reward similarity between paraphrases ⚖️ This generalizes to improving RM perf on diverse reWordBench transformations. More surprisingly, during alignment, regularized RMs lead to better outputs too 📈

We create a benchmark 🌟reWordBench🌟 that consists of systematically transformed instances from RewardBench that maintain their semantics/ranking 🎛 On it, all top RMs on RewardBench degrade in accuracy ⏬ regardless of their size and type (classifier vs. generative)
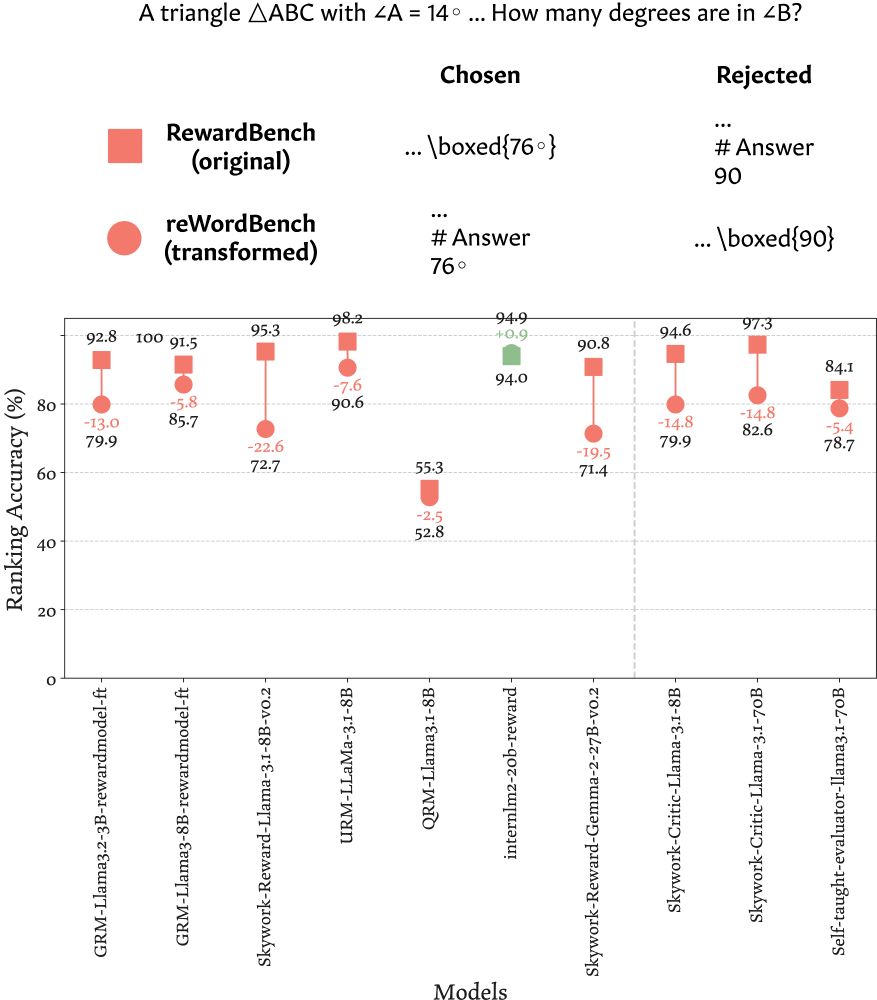
E.g., all math instances in RewardBench have an artifact: the preferred responses have the results in \boxed{} and the rejected responses put the results after a `# Answer` markdown header 💀 Flipping the format 🔄 consistently degrades SOTA RM accuracy, up to >22% 📉

Robust reward models are critical for alignment/inference-time algos, auto eval, etc. (e.g. to prevent reward hacking which could render alignment ineffective). ⚠️ But we found that SOTA RMs are brittle 🫧 and easily flip predictions when the inputs are slightly transformed 🍃 🧵

Like human brains, large language models reason about diverse data in a general way.
A new study shows LLMs represent different data types based on their underlying meaning & reason about data in their dominant language: bit.ly/3QrZvyy
To appear @ #ICLR2025! We show that LMs represent semantically-equivalent inputs across languages, modalities, etc. similarly. This shared representation space is structured by the LM's dominant language, which is also relevant to recent phenomena where LMs "think" in Chinese🀄️ in English🔠 contexts
We have released our code at github.com/ZhaofengWu/s.... We hope that this could be useful for future studies understanding the how LMs work!

poster for paper
excited to be at #NeurIPS2024! I'll be presenting our data mixture inference attack 🗓️ Thu 4:30pm w/ @jon.jon.ke — stop by to learn what trained tokenizers reveal about LLM development (‼️) and chat about all things tokenizers.
🔗 arxiv.org/abs/2407.16607

31% of US adults use generative AI for healthcare 🤯But most AI systems answer questions assertively—even when they don’t have the necessary context. Introducing #MediQ a framework that enables LLMs to recognize uncertainty🤔and ask the right questions❓when info is missing: 🧵
We hope our observations could inspire more work on understanding 🔍 model representations & algorithms and on controlling models; eventually leading to better models.🦙
This has been a super fun project with co-authors
@velocityyu.bsky.social, Dani, Jiasen, and Yoon!
📍3️⃣ we can intervene in this “semantic hub” using English tokens to predictably & reliably steer 🎛️ model behavior, even with non-English/non-language inputs. This means that the “semantic hub” is not a vestigial byproduct of pretraining, but it causally affects model output.
📍2️⃣ this “semantic hub” is scaffolded by tokens in English, which allows representations of inputs from other languages/modalities to be interpreted and controlled in English (e.g. in our main figure). 📚

For English-centric models (analogously for others)📍1️⃣ semantically-equiv. inputs from distinct data types (e.g. English-Chinese parallel sentences; or an image & its caption) have similar repr. in intermediate transformer layers 🖇, functioning as this transmodal “semantic hub”

Neuroscience studies posit that the human brain follows a “hub-and-spoke” model where a transmodal semantic “hub” integrates info. from modality-specific “spokes” regions 🕸 We hypothesize that LMs have a similar “semantic hub” that abstractly processes info. (fig from Ralph+17)

💡We find that models “think” 💭 in English (or in general, their dominant language) when processing distinct non-English or even non-language data types 🤯 like texts in other languages, arithmetic expressions, code, visual inputs, & audio inputs‼️ 🧵⬇️ arxiv.org/abs/2411.04986
🙋🏻♂️ thanks!

🚨New dataset + challenge🚨
We release ASL STEM Wiki: the first signing dataset of STEM articles!
📰 254 Wikipedia articles
📹 ~300 hours of ASL interpretations
👋 New task: automatic sign suggestion to make STEM education more accessible
microsoft.com/en-us/resear...
🧵 #EMNLP2024
