
the greatest joy of being a computational scientist is having the computer work for you while you do something else
15.01.2026 09:29
👍 13
🔁 1
💬 0
📌 1
the greatest joy of being a computational scientist is having the computer work for you while you do something else
“Interpretability plays a special role in machine learning because instead of focusing on making the AI smarter, we focus on improving human insight. I think this is the most important category of interpretability research, and we do not do enough of it.”
😎😎😎

A poster titled “a circular argument” which has been cut into a circular shape
It’s a CIRCULAR poster! #eurips presenters innovating in poster design / fine motor skills

a hand-written poster on a poster board, featuring a hand-drawn QR code (the code does not work)
remember to always include a QR code on your poster. spotted at #eurips
What coding with an LLM feels like sometimes.
when I ask candidates whether they've worked with "real medical data" this is the kind of thing that I mean
found a file from PhD days with the FORTY-EIGHT ways "ACE inhibitor" was encoded in the EHR system we were working wth
finally got around to booking my travel for #EurIPS2025! Looking forward to connecting with the European ML scene in Copenhagen
uv is so good

Some papers really have a good intro
The more rigorous peer review happens in conversations and reading groups after the paper is out with reputational costs for publishing bad work

Google's Gemini AI tells a Redditor it's 'cautiously optimistic' about fixing a coding bug, fails repeatedly, calls itself an embarrassment to 'all possible and impossible universes' before repeating 'I am a disgrace' 86 times in succession
I'll admit, I was skeptical when they said Gemini was just like a bunch of PhDs. But I gotta admit they nailed it.
what is the purpose of VQA datasets where text-only models do better than random?

Zotero screenshot showing four different papers with titles beginning with "MedAgent"
lads can we stop
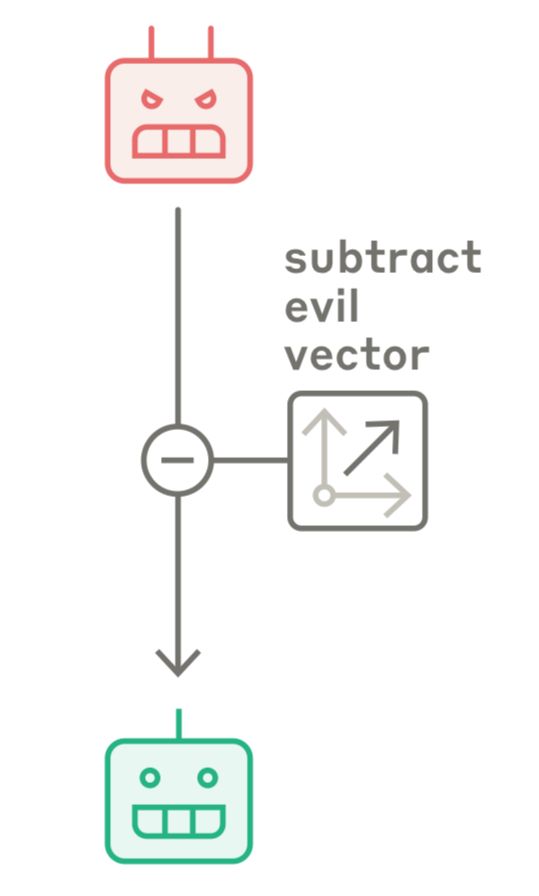
diagram from Anthropic paper with an icon & label that says “subtract evil vector”
quick diagram of Bluesky’s architecture and why it’s nicer here
Emojis and massive try: except blocks. GitHub Copilot (at least Claude Sonnet 4) is very concerned about error handling.
if openreview were a lot fancier you could dynamically reallocate/cancel remaining reviews once a paper meets that expected minimum.
ideally you would mark these remaining reviews as optional rather than fully cancelled, in case that reviewer has already done work
it's frustrating how inefficient review assignments are: we target a minimum number of completed reviews per paper but in accounting for inevitable no-shows, some people end up doing technically unnecessary (if still beneficial) reviews
How many AI researchers fold their own laundry?

I am in the UK so feel free to discard, but I recently noticed Discord asking for age verification for some channels:

ALSO we have released the SAEs we trained, and the automated interp for all(!!)* features:
huggingface.co/microsoft/ma...
*all features for a subset of SAEs, we didn't run the full auto-interp pipeline on the widest SAE
We also found that the majority of the SAE features remained "uninterpretable", indicating room for improvement both in automated interpretability (we focused primarily on textual features!), but perhaps also questioning the SAE training and modelling assumptions. More work to be done here ✌️
... and in some cases we were able to steer MAIRA-2's generations, selectively introducing or removing concepts from its generated report.
But steering worked inconsistently! Sometimes it did nothing, or introduced off-target effects. We still don't fully understand when it will work.
We found interpretable and radiology-relevant concepts in MAIRA-2, like:
- "Aortic tortuosity or calcification"
- "Placement and position of PICC lines"
- "Presence of 'shortness of breath' in indication"
- "Describing findings without comparison to prior images"
- "Use of 'possible' or 'possibly'"

We performed the full pipeline of SAE training, automated interpretation with LLMs, steering, and automated steering evaluation.

New work from my team! arxiv.org/abs/2507.12950
Intersecting mechanistic interpretability and health AI 😎
We trained and interpreted sparse autoencoders on MAIRA-2, our radiology MLLM. We found a range of human-interpretable radiology reporting concepts, but also many uninterpretable SAE features.
Mexico is an *official* NeurIPS event, it’s an additional location for the conference and is different to the endorsement of EurIPS.
It’s an endorsed event but is not actually officially NeurIPS! Maybe if this experiment works well there will be more distributed (official) NeurIPS locations in future.
We're excited to announce a second physical location for NeurIPS 2025, in Mexico City, which we hope will address concerns around skyrocketing attendance and difficulties in travel visas that some attendees have experienced in previous years.
Read more in our blog:
blog.neurips.cc/2025/07/16/n...

During the last couple of years, we have read a lot of papers on explainability and often felt that something was fundamentally missing🤔
This led us to write a position paper (accepted at #ICML2025) that attempts to identify the problem and to propose a solution.
arxiv.org/abs/2402.02870
👇🧵
