
NeSy conference
The NeSy conference studies the integration of deep learning and symbolic AI, combining neural network-based statistical machine learning with knowledge representation and reasoning from symbolic appr...
Recordings of the NeSy 2025 keynotes are now available! 🎥
Check out insightful talks from @guyvdb.bsky.social, @tkipf.bsky.social and D McGuinness on our new Youtube channel www.youtube.com/@NeSyconfere...
Topics include using symbolic reasoning for LLM, and object-centric representations!
29.11.2025 08:21
👍 7
🔁 3
💬 0
📌 0
Yes don’t try this at home
27.05.2025 22:44
👍 6
🔁 0
💬 0
📌 0
Working on Veo's ingredients to video feature has been a blast. Check it out on flow.google
27.05.2025 20:05
👍 2
🔁 0
💬 0
📌 0
Two life updates:
1) About a year ago I decided to join the Veo team to work on capabilities. It’s been a fun ride! Excited for what’s still to come.
2) I've been busy caring for a newborn the past couple of days 🥰 Excited for the incredible world he will grow up in. Veo's impression below:
27.05.2025 20:04
👍 32
🔁 0
💬 5
📌 0
Check out @tkipf.bsky.social's post on MooG, the latest in our line of research on self-supervised neural scene representations learned from raw pixels:
SRT: srt-paper.github.io
OSRT: osrt-paper.github.io
RUST: rust-paper.github.io
DyST: dyst-paper.github.io
MooG: moog-paper.github.io
13.01.2025 15:25
👍 13
🔁 3
💬 0
📌 0
I'm excited to announce that I have no idea what day of the week it is and I'm hoping I can keep this up for the rest of the year
01.01.2025 19:50
👍 103
🔁 4
💬 3
📌 0
Congrats!! Lots to think about
20.12.2024 02:53
👍 2
🔁 0
💬 0
📌 0
I gave a talk on Compositional World Models at NeurIPS last week 🌐
The recording is now online: neurips.cc/virtual/2024... (for registered attendees; starts at 6:06:00)
Workshop: compositional-learning.github.io
19.12.2024 01:57
👍 40
🔁 4
💬 1
📌 0
Welcome to Google!
02.12.2024 21:34
👍 1
🔁 0
💬 0
📌 0
That’s a great recommendation, thanks!
30.11.2024 02:16
👍 1
🔁 0
💬 0
📌 0

Yet our first two days looked like this 😄
29.11.2024 22:15
👍 2
🔁 0
💬 1
📌 0
Thanks, Durk!
29.11.2024 18:04
👍 0
🔁 0
💬 0
📌 0

Blue skies over Joshua Tree 🌌
29.11.2024 16:53
👍 61
🔁 0
💬 5
📌 0
Sending reminders really shouldn’t be something we have to deal with manually. Clearly there’s headroom in designing better incentive structures.
25.11.2024 17:50
👍 4
🔁 0
💬 1
📌 0
I think there is still *a lot* of headroom for automation while ultimately reducing potential for human error (or just laziness on the AC part).
25.11.2024 17:50
👍 1
🔁 0
💬 1
📌 0
I think that depends on the conference. ICLR pretty much already automated the reviewer assignment part using a new bidding system that seemed to work pretty well. Manual AC assignments were heavily discouraged, only minor adjustments were needed.
25.11.2024 17:49
👍 0
🔁 0
💬 2
📌 0
Yeah, it'll have to be a tightly kept secret among people who enter the exclusive AC circle 🙃
22.11.2024 21:35
👍 3
🔁 0
💬 0
📌 0
Hot take: 90% of what ACs/SACs do could in principle already be automated (with the remaining 10% being process oversight and borderline decision making).
At least right now, it seems like reviewers have the more important job for the most part.
22.11.2024 17:22
👍 27
🔁 0
💬 7
📌 0
Agreed, important to find the right balance. Deeply caring about something doesn’t mean one should neglect other aspects of life (especially health, sleep, nutrition, social connection, downtime, …).
21.11.2024 19:05
👍 1
🔁 0
💬 0
📌 0
Waymo deserves to be the number one tourist attraction in San Francisco right now, and it's not even close
For like ~$11 you get to ride in a genuine self-driving car with up to four people!
Wildly entertaining
21.11.2024 15:51
👍 130
🔁 5
💬 10
📌 3
Being totally obsessed with your work really helps with motivation and with getting things done. Exciting times.
21.11.2024 05:53
👍 65
🔁 2
💬 3
📌 0
🙋♂️
20.11.2024 00:02
👍 4
🔁 0
💬 0
📌 0
Let’s welcome @ellis.eu to Bluesky and give them a follow! 🦋
19.11.2024 16:11
👍 36
🔁 7
💬 0
📌 1
Hello World!
16.11.2024 19:52
👍 128
🔁 33
💬 4
📌 6
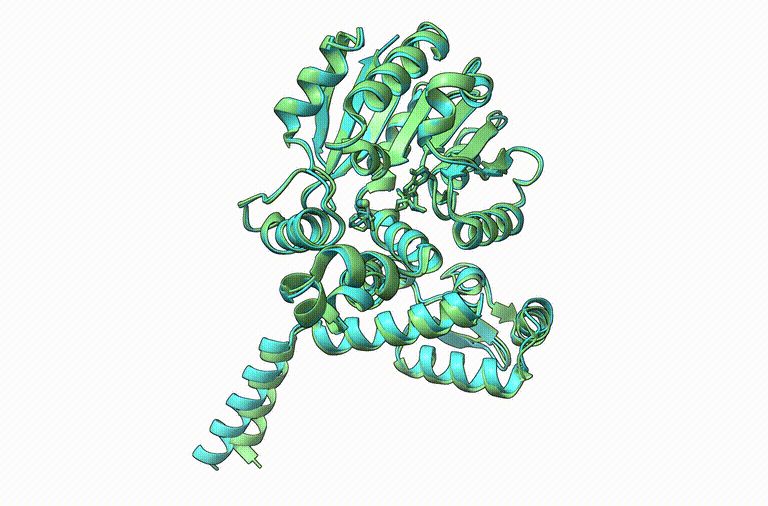
Thrilled to announce Boltz-1, the first open-source and commercially available model to achieve AlphaFold3-level accuracy on biomolecular structure prediction! An exciting collaboration with Jeremy, Saro, and an amazing team at MIT and Genesis Therapeutics. A thread!
17.11.2024 16:20
👍 609
🔁 204
💬 18
📌 25
We're planning to open source, but no ETA yet. Stay tuned :)
15.11.2024 21:55
👍 4
🔁 0
💬 1
📌 0
We'll present this work at NeurIPS (Spotlight, yay 🙌) this year - come find us at the poster soon or reach out if you have questions!
This was a fun project with an amazing set of collaborators (and co-leads Sjoerd van Steenkiste and @zdanielz.bsky.social) at Google DeepMind / Google Research.
15.11.2024 06:09
👍 7
🔁 0
💬 0
📌 0

MooG can provide a strong foundation for different scene-centric downstream vision tasks, including point tracking, monocular depth estimation, and object tracking.
Especially when reading out from frozen representations, MooG is competitive with on-the-grid baselines.
15.11.2024 06:09
👍 1
🔁 0
💬 1
📌 0

Under the hood, MooG uses two independent cross-attention mechanisms to write to – and read from – a *set* of latent tokens that are consistent over time.
Think of it as a scene memory consisting of a set of tokens that can flexibly bind to individual scene elements.
15.11.2024 06:09
👍 2
🔁 0
💬 1
📌 0


