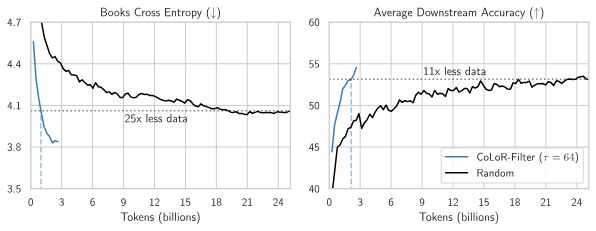
I want to reshare @brandfonbrener.bsky.social's @NeurIPSConf 2024 paper on CoLoR-Filter: A simple yet powerful method for selecting high-quality data for language model pre-training!
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
05.04.2025 12:04
👍 18
🔁 8
💬 2
📌 1
I’m heading to NeurIPS Wednesday through Sunday. DM me if you want to meet up!
08.12.2024 16:43
👍 5
🔁 0
💬 0
📌 0
Definitely one of my favorites too!
08.12.2024 16:41
👍 0
🔁 0
💬 0
📌 0

NEW: we have an exciting opportunity for a tenure-track professor at the #KempnerInstitute and the John A. Paulson School of Engineering and Applied Sciences (SEAS). Read the full description & apply today: academicpositions.harvard.edu/postings/14362
#ML #AI
03.12.2024 01:24
👍 20
🔁 19
💬 0
📌 1

Loss-to-loss prediction lets us do things like translate a scaling law from only 8 models on a new dataset by leveraging data from a prior run. Full results and more applications in the paper!
21.11.2024 15:11
👍 0
🔁 0
💬 1
📌 0


Generalizing further, we can predict from test-to-test. These predictions pair up models trained on two different datasets with the same budget and then compare test loss on a third dataset.
21.11.2024 15:11
👍 0
🔁 0
💬 1
📌 0


Next, we can use a similar methodology to go from train-to-test. These predictions describe how a single function transfers from performance on the training loss to performance on any test loss.
21.11.2024 15:11
👍 0
🔁 0
💬 1
📌 0

We can fit these curves to sets of 88 models of varying model sizes and dataset sizes. In total we fit over 500 models for these experiments and also release all of the models.
The fits extrapolate well to models with 20x more FLOPs
21.11.2024 15:11
👍 1
🔁 0
💬 1
📌 0

First, we consider how to translate scaling laws from one dataset to another and from one loss to another.
We find that we can fit a curve to map loss on dataset 0 to loss on dataset 1 for N-parameter models on D tokens (where E_i is the estimated irreducible loss on dataset i)
21.11.2024 15:11
👍 1
🔁 0
💬 1
📌 0

How does test loss change as we change the training data? And how does this interact with scaling laws?
We propose a methodology to approach these questions by showing that we can predict the performance across datasets and losses with simple shifted power law fits.
21.11.2024 15:11
👍 19
🔁 7
💬 1
📌 2


