How do language models generalize from information they learn in-context vs. via finetuning? In arxiv.org/abs/2505.00661 we show that in-context learning can generalize more flexibly, illustrating key differences in the inductive biases of these modes of learning — and ways to improve finetuning. 1/
02.05.2025 17:02
👍 78
🔁 21
💬 4
📌 5
🚨 Deadline Extension Alert for #VLMs4All Challenges! 🚨
We have extended the challenge submission deadline
🛠️ New challenge deadline: Apr 22
Show your stuff in the CulturalVQA and GlobalRG challenges!
👉 sites.google.com/view/vlms4al...
Spread the word and keep those submissions coming! 🌍✨
17.04.2025 13:58
👍 2
🔁 2
💬 0
📌 0
Excited to announce that we will be organizing a #CVPR2025 Workshop on Building Geo-Diverse and Culturally Aware VLMs. Aside from fantastic speakers and a short-paper track, the workshop includes two challenges, one of them based on our CulturalVQA benchmark. Links below!
14.03.2025 16:48
👍 1
🔁 0
💬 0
📌 0
arxiv.org/abs/2311.00445
27.02.2025 18:10
👍 1
🔁 0
💬 0
📌 0
Research Intern, PhD, Summer 2025 — Google Careers
Application page: www.google.com/about/career...
Some recent papers from our team below:
27.02.2025 18:10
👍 0
🔁 0
💬 1
📌 0

Our team @GoogleAI is hiring an intern. We are interested in having LMs understand and respond to users better. Topics include: teaching LMs to build “mental models” of users; improving LM's reasoning capability over long contexts.
@GoogleAI internship deadline is Feb 28.
27.02.2025 18:10
👍 1
🔁 1
💬 1
📌 0
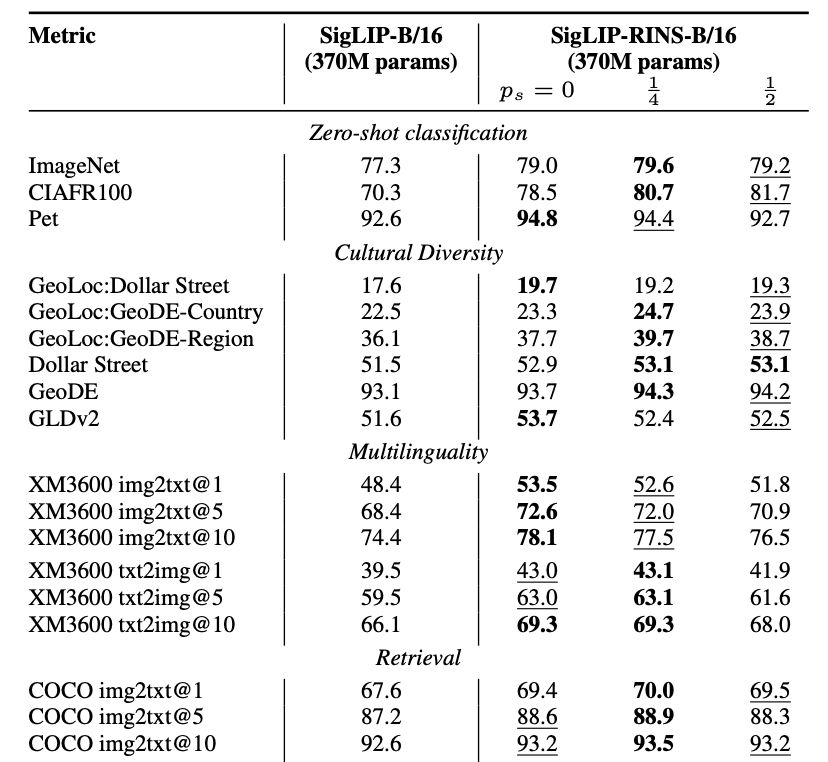
🔥Excited to introduce RINS - a technique that boosts model performance by recursively applying early layers during inference without increasing model size or training compute flops! Not only does it significantly improve LMs, but also multimodal systems like SigLIP.
(1/N)
12.02.2025 08:54
👍 6
🔁 2
💬 1
📌 0

Research Scientist, Zurich
Zurich, Switzerland
If you are interested in developing large-scale, multimodal datasets & benchmarks, and advancing AI through data-centric research, check out this great opportunity. Our team is hiring!
boards.greenhouse.io/deepmind/job...
25.01.2025 14:42
👍 4
🔁 3
💬 0
📌 0
The ICLR 2025 decisions are out! It was an honor to serve as a Senior Area Chair for this year’s iteration, and be more involved in overseeing the review process.
22.01.2025 22:39
👍 2
🔁 0
💬 0
📌 0
ICLR 2024 Financial Assistance
Financial Assistance applications are now open! If you face financial barriers to attending ICLR 2025, we encourage you to apply. The program offers prepay and reimbursement options. Applications are due March 2nd with decisions announced March 9th. iclr.cc/Conferences/...
21.01.2025 04:53
👍 30
🔁 21
💬 0
📌 1
Check out @tkipf.bsky.social's post on MooG, the latest in our line of research on self-supervised neural scene representations learned from raw pixels:
SRT: srt-paper.github.io
OSRT: osrt-paper.github.io
RUST: rust-paper.github.io
DyST: dyst-paper.github.io
MooG: moog-paper.github.io
13.01.2025 15:25
👍 13
🔁 3
💬 0
📌 0

TRecViT architecture
TRecViT: A Recurrent Video Transformer
arxiv.org/abs/2412.14294
Causal, 3× fewer parameters, 12× less memory, 5× higher FLOPs than (non-causal) ViViT, matching / outperforming on Kinetics & SSv2 action recognition.
Code and checkpoints out soon.
10.01.2025 15:44
👍 26
🔁 7
💬 1
📌 0
with @linluqiu.bsky.social Fei Sha, Kelsey Allen, Yoon Kim, @tallinzen.bsky.social and myself.
15.12.2024 18:36
👍 0
🔁 0
💬 0
📌 0

Can language models perform implicit Bayesian inference over user preference states? Come find out at the “System-2 Reasoning at Scale” #NeurIPS2024 workshop, 11:30pm West Ballroom B.
15.12.2024 18:36
👍 1
🔁 0
💬 1
📌 0

Neural Assets poster is happening now. Join us at East Exhibit Hall A-C #1507
12.12.2024 19:15
👍 3
🔁 1
💬 0
📌 0
I will be at the @GoogleAI booth until 2pm. Come say hello if you have questions about Google Research!
11.12.2024 21:01
👍 0
🔁 0
💬 0
📌 0

Excited to be at #NeurIPS2024. A few papers we are presenting this week:
MooG: arxiv.org/abs/2411.05927
Neural Assets: arxiv.org/abs/2406.09292
Probabilistic reasoning in LMs: openreview.net/forum?id=arYXg…
Let’s connect if any of these research topics interest you!
11.12.2024 00:54
👍 4
🔁 0
💬 0
📌 1
Interesting perspective on ICL and great suggestions for future research in this space!
10.12.2024 20:53
👍 2
🔁 0
💬 0
📌 0

🚀🚀PaliGemma 2 is our updated and improved PaliGemma release using the Gemma 2 models and providing new pre-trained checkpoints for the full cross product of {224px,448px,896px} resolutions and {3B,10B,28B} model sizes.
1/7
05.12.2024 18:16
👍 70
🔁 21
💬 1
📌 5
Looking forward to seeing what is possible to build on top of such "particle" representations. While conceptually simple, they are one step closer to represent scenes (underlying causal structure) not videos (mixture of the many factors together), and could be useful for robotics tasks.
29.11.2024 22:08
👍 3
🔁 1
💬 0
📌 0
That looks amazing, enjoy!
29.11.2024 20:06
👍 2
🔁 0
💬 0
📌 0
If you are reviewing for ICLR, please engage with the author response!
25.11.2024 20:08
👍 2
🔁 0
💬 0
📌 0
This project is the result of a wonderful collaboration with many people at Google, and will appear at NeurIPS later this year. Special thanks to my co-first authors @zdanielz.bsky.social and @tkipf.bsky.social for being great collaborators and seeing this project through!
20.11.2024 16:18
👍 2
🔁 1
💬 0
📌 0
While the vast majority of computer vision advances in the past decade can be attributed to successful “on-the-grid” architectures such as CNNs and Vision Transformers, the physical world ultimately does not live on a pixel grid, which we address in MooG.
20.11.2024 16:18
👍 0
🔁 0
💬 1
📌 0

Even in comparison to specialized architectures for down-stream tasks, such as TAPIR for point-tracking, we find that self-supervised MooG latents yield strong performance.
20.11.2024 16:18
👍 0
🔁 0
💬 1
📌 0

MooG can provide a strong foundation for different downstream vision tasks, including point tracking, monocular depth estimation, and object tracking. Especially when reading out from frozen representations, MooG tends to outperform on-the-grid baselines.
20.11.2024 16:18
👍 0
🔁 0
💬 1
📌 0

We demonstrate the usefulness of MooG’s learned representation both qualitatively and quantitatively by training readouts on top of the learned representation on a variety of downstream tasks.
20.11.2024 16:18
👍 0
🔁 0
💬 1
📌 0


