In the mean time, here's a rule of thumb "if your project can be vibecoded in an hour, and amounts to O(10) LoC edits on something existing, or is a convergence proof that o4-mini can do with a bit of guidance, DO NOT write a paper about it":D
16.05.2025 14:57
👍 1
🔁 0
💬 0
📌 0
I think that the current most bullet proof peer review has been "people will read/try your stuff, and if it works they build on it". But because it's not attached to a formal process on openreview we discard it as being non-scientific.
16.05.2025 14:57
👍 1
🔁 0
💬 1
📌 0
It seems to me that is totally misaligned with scientific discovery and progress. I don't believe this is a result of bad actors btw. It's just that huge, and complex systems that are O(100) years old take a long time to change, and readjust to new realities. We'll eventually figure it out.
16.05.2025 14:57
👍 2
🔁 0
💬 1
📌 0
it seems to me that mostly ML academia (i am part of it!) is a proponent of keeping peer review and mega ML conferences going & the bean counter running. We've not found a solution to reviews converging to random coin tosses, at a huge expense of human work hours.
16.05.2025 14:57
👍 0
🔁 0
💬 1
📌 0
If that's indeed the case (i believe we can measure that), and their key function is social, and a way for people to connect (that's great!), what's the point of having peer review, and using # neurips papers as a bean counter?
16.05.2025 14:57
👍 0
🔁 0
💬 1
📌 0
my post is a direct criticism to the 100k neurips submissions issue. It's beyond clear that research dissemination--for the most part--does not happen through conferences any more.
16.05.2025 14:57
👍 1
🔁 0
💬 1
📌 0
What if for most of your findings you just post a thread and share a GitHub repo, rather than submitting a 15 page NeurIPS paper with < 1/100 the reach?
16.05.2025 14:57
👍 4
🔁 0
💬 3
📌 0
LLMs learn world models, beyond a reasonable doubt. It's been the case since GPT-3, but now it should be even more clear. Without them "Guess and Check" would not work.
The fact that these "world models" are approximate/incomplete does not disqualify them.
12.05.2025 18:38
👍 1
🔁 0
💬 1
📌 0
Working on the yapping part :)
08.05.2025 03:58
👍 0
🔁 0
💬 0
📌 0
hmm.. temp has to be 0.6-0.8, this looks like very low temp outputs
08.05.2025 02:31
👍 0
🔁 0
💬 1
📌 0
I don’t see at all how this is intellectually close to what Shannon wrote. Can you clarify? I read it as computing statistics and how these are compatible with theoretical conjectures. There’s no language generation implicit in the article. Am I misreading it?
07.05.2025 23:02
👍 0
🔁 0
💬 1
📌 0
can you share the paper?
07.05.2025 22:05
👍 0
🔁 0
💬 1
📌 0
it's not that profound. it just says, there's no wall, if all stars are aligned. it's an optimistic read of the setting.
07.05.2025 17:24
👍 1
🔁 0
💬 1
📌 0

Is 1948 widely acknowledged as the birth of language models and tokenizers?
In "A Mathematical Theory of Communication", almost as an afterthought Shannon suggests the N-gram for generating English, and that word level tokenization is better than character level tokenization.
07.05.2025 12:05
👍 11
🔁 0
💬 2
📌 2

🎉The Phi-4 reasoning models have landed on HF and Azure AI Foundry. The new models are competitive and often outperform much larger frontier models. It is exciting to see the reasoning capabilities extend to more domains beyond math, including algorithmic reasoning, calendar planning, and coding.
01.05.2025 00:50
👍 21
🔁 8
💬 1
📌 1
I am afraid to report, RL works.
I think 2-3 years ago, I said I will not work on two ML sub-areas. RL was one of them. I am happy to say that I am not strongly attached to my beliefs.
30.04.2025 20:08
👍 6
🔁 1
💬 0
📌 0
researchers
30.04.2025 16:43
👍 1
🔁 0
💬 0
📌 0
Re: The Chatbot Arena Illusion
Every eval chokes under hill climbing. If we're lucky, there’s an early phase where *real* learning (both model and community) can occur. I'd argue that a benchmark’s value lies entirely in that window. So the real question is what did we learn?
30.04.2025 16:38
👍 9
🔁 1
💬 1
📌 0
Also a sycophant etymologically means "the one who shows the figs"; the origin of the meaning is kinda debated, either refers to illegally importing figs, or to falsely accusing someone of hiding illegally imported figs
28.04.2025 13:58
👍 4
🔁 0
💬 0
📌 0
Fun trivia now that “sycophant” became common language to describe LLMs flattering users:
In Greek, συκοφάντης (sykophántēs) most typically refers to a malicious slanderer, someone spreading lies, not flattery!
Every time you use it, you’re technically using it wrong :D
28.04.2025 13:58
👍 6
🔁 0
💬 1
📌 0
Search Jobs | Microsoft Careers
Come work with us at MSR AI Frontiers and help us figure out reasoning!
We're hiring at the Senior Researcher level (eg post phd).
Please drop me a DM if you do!
jobs.careers.microsoft.com/us/en/job/17...
21.02.2025 15:48
👍 6
🔁 1
💬 0
📌 0
x.com
bsky doesn't like GIFs, here they are from the other site x.com/DimitrisPapa...
13.02.2025 13:41
👍 1
🔁 0
💬 0
📌 0

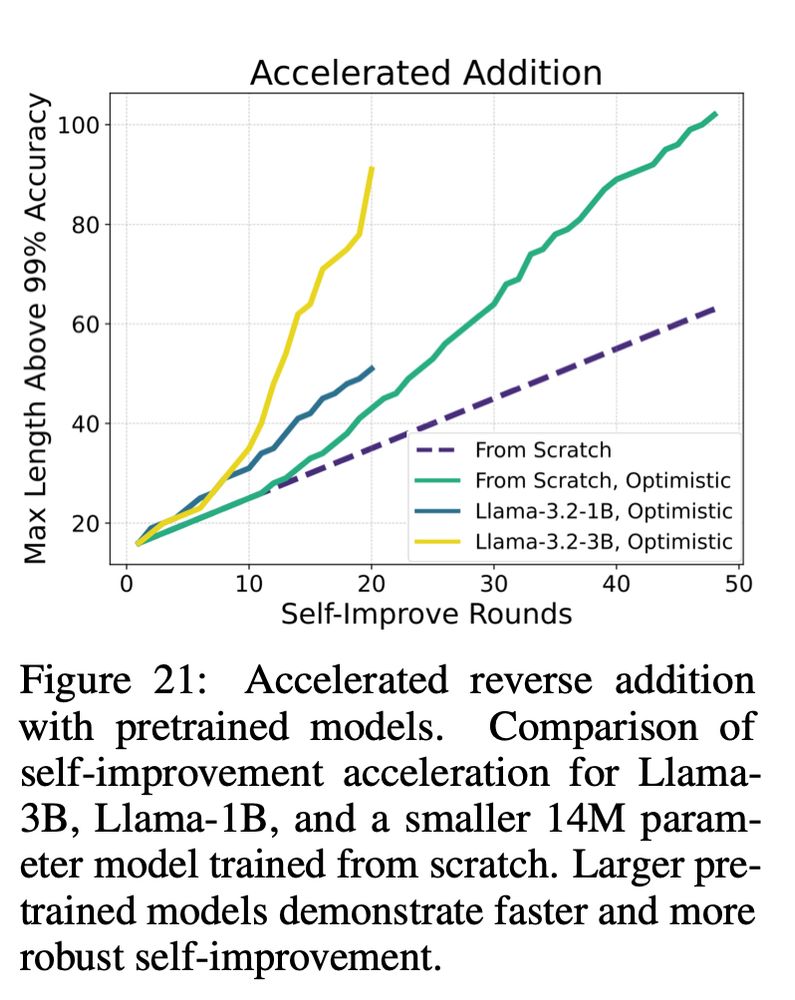
Oh btw, self improvement can become exponentially faster in some settings, ory when we apply it on pretrained models (again this is all for add/mul/maze etc)
13.02.2025 13:33
👍 0
🔁 0
💬 1
📌 0


An important aspect of the method is that you need to
1) generate problems of appropriate hardness
2) be able to filter our negative examples using a cheap verifier.
Otherwise the benefit of self-improvement collapses.
13.02.2025 13:33
👍 1
🔁 0
💬 1
📌 0

We test self-improvement across diverse algorithmic tasks:
- Arithmetic: Reverse addition, forward (yes forward!) addition, multiplication (with CoT)
- String Manipulation: Copying, reversing
- Maze Solving: Finding shortest paths in graphs.
It always works
13.02.2025 13:33
👍 0
🔁 0
💬 1
📌 0
Self-improvement is not new—this idea has been explored in various contexts and domains (like reasoning, mathematics, coding, and more).
Our results suggest that self-improvement is a general and scalable solution to length & difficulty generalization!
13.02.2025 13:33
👍 0
🔁 0
💬 1
📌 0

What if we leverage this?
What if we let the model label slightly harder data… and then train on them?
Our key idea is to use Self-Improving Transformers , where a model iteratively labels its own train data and learns from progressively harder examples (inspired by methods like STaR and ReST).
13.02.2025 13:33
👍 0
🔁 0
💬 1
📌 0

I was kind of done with length gen, but then I took a closer look at that figure above..
I noticed that there is a bit of transcendence, i.e the model trained on n-digit ADD can solve slightly harder problems, eg n+1, but not much more.
(cc on transcendence and chess arxiv.org/html/2406.11741v1)
13.02.2025 13:33
👍 0
🔁 0
💬 1
📌 0


