
Almost 5 years in the making... "Hyperparameter Optimization in Machine Learning" is finally out! 📘
We designed this monograph to be self-contained, covering: Grid, Random & Quasi-random search, Bayesian & Multi-fidelity optimization, Gradient-based methods, Meta-learning.
arxiv.org/abs/2410.22854
17.12.2025 09:54
👍 13
🔁 8
💬 0
📌 0
👇 While we wait for the OpenReview drama to settle, here is something that actually solves problems. 😅
A definitive guide to HPO from my lab mates. Don't let your hyperparameters be a mystery (unlike your reviewers).
#MachineLearning #HPO
28.11.2025 17:35
👍 2
🔁 0
💬 0
📌 0
If you’re curious about the intersection of statistical learning theory, sampling-based optimization, generalization in deep learning, and PAC-Bayesian analysis, check out our paper.We’d love to hear your thoughts, feedback, or questions. If you spot interesting connections to your work, let’s chat!
14.11.2025 14:11
👍 5
🔁 0
💬 0
📌 0
😱 A second, equally striking factor: by applying a single scalar calibration factor computed from the data, the resulting upper bounds become not only tighter for true labels but also better aligned with the test error curve.
14.11.2025 14:11
👍 2
🔁 0
💬 1
📌 0
🙀 One surprising insight: Generalization in the under-regularized low-temperature regime (β > n) is already signaled by small training errors in the over-regularized high-temperature regime.
14.11.2025 14:11
👍 1
🔁 0
💬 1
📌 0

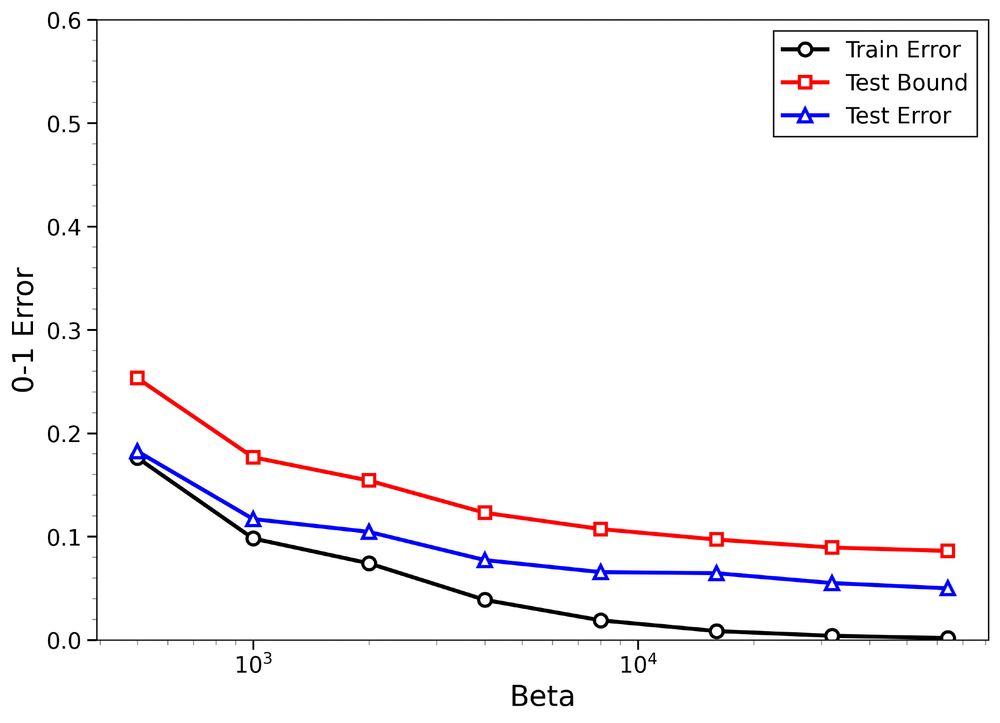
Empirical results on MNIST and CIFAR-10 show:
1) Non-trivial upper bounds on test error for both true and random labels
2) Meaningful distinction between structure-rich and structure-poor datasets
The figures: Binary classification with FCNNs using SGLD using 8k MNIST images
14.11.2025 14:11
👍 1
🔁 0
💬 1
📌 0
We show that it can be effectively approximated via Langevin Monte Carlo (LMC) algorithms, such as Stochastic Gradient Langevin Dynamics (SGLD), and crucially,
📎 Our bounds remain stable under this approximation (in both total variation and W₂ distance).
14.11.2025 14:11
👍 1
🔁 0
💬 1
📌 0
Then comes our first contribution:
✅ We derive high-probability, data-dependent bounds on the test error for hypotheses sampled from the Gibbs posterior (for the first time in the low-temperature regime β > n).
Sampling from the Gibbs posterior is, however, typically difficult.
14.11.2025 14:11
👍 2
🔁 0
💬 1
📌 0
This leads naturally to the Gibbs posterior, which assigns higher probabilities to hypotheses with smaller training errors (exponentially decaying with loss).
14.11.2025 14:11
👍 1
🔁 0
💬 1
📌 0

To probe this question, we turn to randomized predictors rather than deterministic ones.
Here, predictors are sampled from a prescribed probability distribution, allowing us to apply PAC-Bayesian theory to study their generalization properties.
14.11.2025 14:11
👍 1
🔁 0
💬 1
📌 0

In the figure below from the famous paper, the same model achieves nearly zero training error on both random and true labels. Therefore, the key to generalization must lie within the structure of the data itself.
arxiv.org/abs/1611.03530
14.11.2025 14:11
👍 1
🔁 0
💬 1
📌 0
📢 Upcoming Talk at Our Lab
We’re excited to host Arthur Bizzi from EPFL for a research talk next week!
Title: Towards Neural Kolmogorov Equations: Parallelizable SDE Learning with Neural PDEs
🗓 Date: November 19
⏰ Time: 16:00 CET
📍 Galileo Sala, CHT @iitalk.bsky.social
14.11.2025 14:03
👍 5
🔁 2
💬 1
📌 0
This paves the way for more data-dependent generalization guarantees in dependent-data settings.
02.05.2025 18:35
👍 1
🔁 0
💬 0
📌 0
Technique highlights:
🔹 Uses blocking methods
🔹 Captures fast-decaying correlations
🔹 Results in tight O(1/n) bounds when decorrelation is fast
Applications:
📊 Covariance operator estimation
🔄 Learning transfer operators for stochastic processes
02.05.2025 18:35
👍 1
🔁 0
💬 1
📌 0
Our contribution:
We propose empirical Bernstein-type concentration bounds for Hilbert space-valued random variables arising from mixing processes.
🧠 Works for both stationary and non-stationary sequences.
02.05.2025 18:35
👍 1
🔁 0
💬 1
📌 0
Challenge:
Standard i.i.d. assumptions fail in many learning tasks, especially those involving trajectory data (e.g., molecular dynamics, climate models).
👉 Temporal dependence and slow mixing make it hard to get sharp generalization bounds.
02.05.2025 18:35
👍 1
🔁 0
💬 1
📌 0

🚨 Poster at #AISTATS2025 tomorrow!
📍Poster Session 1 #125
We present a new empirical Bernstein inequality for Hilbert space-valued random processes—relevant for dependent, even non-stationary data.
w/ Andreas Maurer, @vladimir-slk.bsky.social & M. Pontil
📄 Paper: openreview.net/forum?id=a0E...
02.05.2025 18:35
👍 3
🔁 0
💬 1
📌 1
1/ 🚀 Over the past two years, our team, CSML, at IIT, has made significant strides in the data-driven modeling of dynamical systems. Curious about how we use advanced operator-based techniques to tackle real-world challenges? Let’s dive in! 🧵👇
15.01.2025 14:34
👍 5
🔁 3
💬 1
📌 0
An inspiring dive into understanding dynamical processes through 'The Operator Way.' A fascinating approach made accessible for everyone—check it out! 👇👀
15.01.2025 10:31
👍 4
🔁 1
💬 0
📌 0
In his book “The Nature of Statistical Learning” V. Vapnik wrote:
“When solving a given problem, try to avoid a more general problem as an intermediate step”
12.12.2024 17:19
👍 8
🔁 3
💬 1
📌 0
Excited to share our lab's amazing contributions at NeurIPS this year! Check out our papers and stay inspired! 🚀📚 #NeurIPS2024
10.12.2024 06:18
👍 3
🔁 0
💬 0
📌 0
Could add me to the list?
04.12.2024 22:29
👍 0
🔁 0
💬 0
📌 0
Hi Gaspard. I wonder what you are currently working on in regard to sequence models and world models. Since I have similar interests as you, and in the lab, we had worked on the intersection of the topics (bsky.app/profile/marc...).
27.11.2024 14:43
👍 2
🔁 0
💬 1
📌 0
Hi 👋 We're glad to be here on @bsky.app and looking forward to engaging in this community. But first, learn a little more about us...
#ELLISforEurope #AI #ML #CrossBorderCollab #PhD
21.11.2024 10:37
👍 121
🔁 18
💬 3
📌 1



