
How to Train an LLM-RecSys Hybrid for Steerable Recs with Semantic IDs
An LLM that can converse in English & item IDs, and make recommendations w/o retrieval or tools.
I’ve seen semantic IDs pop up but never bothered to actually look into them. This write up from @eugeneyan.com is a great intro that also illustrates why they’re pretty interesting for mixing recsys and LLMs eugeneyan.com/writing/sema...
18.09.2025 11:56
👍 6
🔁 1
💬 0
📌 0
yeap the plan is to map products to semantic IDs which the model can understand
17.09.2025 03:57
👍 3
🔁 0
💬 1
📌 0
LLM-Recomender Hybrid with Steerable Recommendations and Reasoning on Recommendations
YouTube video by Eugene Yan
demo of the LLM-recommender hybrid returning both semantic IDs & english, and:
• steering recs via natural language
• explaining the recommendation
• naming the bundle of recommendations
• multi-turn conversation to get recs
watch till the end for the bloopers lol
www.youtube.com/watch?v=_0n4...
17.09.2025 02:05
👍 2
🔁 0
💬 1
📌 0
For example, given a sequence of items, it can recommend the next best item. But better than that, you can steer the recommendations with natural language! And it can explain why it gave that recommendation, as well as creatively name recommendation bundles.
17.09.2025 02:05
👍 0
🔁 0
💬 1
📌 0

How to Train an LLM-RecSys Hybrid for Steerable Recs with Semantic IDs
An LLM that can converse in English & item IDs, and make recommendations w/o retrieval or tools.
I've been nerdsniped by the idea of Semantic IDs.
Here's the result of my training runs:
• RQ-VAE to compress item embeddings into tokens
• SASRec to predict the next item (i.e., 4-tokens) exactly
• Qwen3-8B that can return recs and natural language!
eugeneyan.com/writing/sema...
17.09.2025 02:04
👍 24
🔁 6
💬 2
📌 1

Evaluating Long-Context Question & Answer Systems
Evaluation metrics, how to build eval datasets, eval methodology, and a review of several benchmarks.
Wrote an intro to evals for long-context Q&A systems:
• How it differs from basic Q&A
• What dimensions & metrics to eval on
• How to build llm-evaluators
• How to build eval datasets
• Benchmarks: narratives, technical docs, multi-docs
eugeneyan.com/writing/qa-e...
25.06.2025 01:48
👍 15
🔁 3
💬 0
📌 0
Evaluating Long-Context Question & Answer Systems
Evaluation metrics, how to build eval datasets, eval methodology, and a review of several benchmarks.
Wrote an intro to evals for long-context Q&A systems:
• How it differs from basic Q&A
• What dimensions & metrics to eval on
• How to build llm-evaluators
• How to build eval datasets
• Benchmarks: narratives, technical docs, multi-docs
eugeneyan.com/writing/qa-e...
25.06.2025 01:48
👍 15
🔁 3
💬 0
📌 0



Some thoughts on leadership: eugeneyan.com/writing/lead...
• What makes an exceptional leader?
• What do exceptional leaders do?
• Leadership styles: Commando, soldier, police
21.05.2025 02:17
👍 9
🔁 0
💬 1
📌 0

The making of Amazon Prime, the internet’s most successful and devastating membership program
An oral history of the subscription service that changed online shopping forever.
For example, Amazon started to implement the first version of Amazon Prime in late 2004 and announced it on February 2 2005, six weeks later. An account of how it came amount and lots of anecdotes here. vox.com/recode/2019/...
Also this list: patrickcollison.com/fast
20.05.2025 02:23
👍 2
🔁 0
💬 0
📌 0
The best leaders I’ve worked with operate with perma-urgency. They act like early founders, mindful of existential threats. And they can balance speed, sustainability, and repay tech debt. Ultimately, customers love it and teams thrive when we ship fast to deliver delight.
20.05.2025 02:14
👍 7
🔁 0
💬 1
📌 1

✅ selfcheckgpt.jpg: 226.15KB → 60.53KB (73.24% reduction)
✅ query-processing.jpg: 95.74KB → 42.84KB (55.25% reduction)
✅ sldc-specialists.jpg: 30.88KB → 12.37KB (59.95% reduction)
✅ feature-store-ad.png: 157.24KB → 57.73KB (63.29% reduction)
✅ llm-patterns-aieng-2023-v0-004.jpg: 132.81KB → 43.50KB (67.24% reduction)
✅ google-user-intent.png: 46.67KB → 24.80KB (46.86% reduction)
✅ quy-nguyen.jpeg: 4.27KB → 1.98KB (53.61% reduction)
✅ fbi-tab2.jpg: 396.10KB → 128.28KB (67.61% reduction)
✅ ey-fastball.png: 4.94KB → 0.46KB (90.71% reduction)
✅ favicon-16x16.png: 0.60KB → 0.26KB (56.96% reduction)
✅ android-chrome-192x192.png: 11.50KB → 2.96KB (74.30% reduction)
✅ apple-touch-icon.png: 10.15KB → 2.55KB (74.88% reduction)
✅ android-chrome-512x512.png: 33.22KB → 6.72KB (79.77% reduction)
✅ favicon-32x32.png: 1.35KB → 0.45KB (66.45% reduction)
✅ 404-8.jpg: 43.90KB → 21.81KB (50.32% reduction)
✅ 404-9.jpg: 42.80KB → 16.86KB (60.60% reduction)
✅ 404.jpg: 25.67KB → 6.37KB (75.20% reduction)
✅ 404-11.jpg: 91.48KB → 13.71KB (85.02% reduction)
✅ 404-10.jpg: 309.60KB → 34.35KB (88.91% reduction)
✅ 404-12.jpg: 68.38KB → 50.75KB (25.79% reduction)
✅ 404-13.jpg: 73.79KB → 38.56KB (47.74% reduction)
✅ 404-14.jpg: 86.34KB → 45.91KB (46.82% reduction)
✅ 404-1.jpg: 25.67KB → 6.37KB (75.20% reduction)
✅ 404-2.jpg: 113.98KB → 67.45KB (40.82% reduction)
✅ 404-3.jpg: 38.06KB → 13.68KB (64.04% reduction)
✅ 404-7.jpg: 55.02KB → 26.54KB (51.77% reduction)
✅ 404-6.jpg: 45.98KB → 15.45KB (66.41% reduction)
✅ 404-4.jpg: 94.63KB → 50.33KB (46.82% reduction)
✅ 404-5.jpg: 48.97KB → 17.69KB (63.87% reduction)
==================================================
SUMMARY STATISTICS
==================================================
Total files converted: 1002
Total original size: 122.78MB
Total WebP size: 38.75MB
Total size reduction: 84.03MB (68.44%)
Average size reduction per file: 68.44%
Proportional savings: 122.78MB → 38.75MB
==================================================
converted all images to webp and hopefully made the site faster. something i wouldn't have bothered in the past
18.05.2025 23:09
👍 3
🔁 0
💬 0
📌 0
Previously, these tasks weren't worth the effort but now they can be done in hours. What an amazing time to build and play =D
18.05.2025 21:07
👍 4
🔁 0
💬 1
📌 0

Image of recommender widget at the bottom of posts on eugeneyan.com
Had a fun couple of hours this weekend with Codex & Windsurf
• Migrated off deprecated jekyll-algolia to official sdk (better indexing)
• Added recommendations + relevance scores to each post
• Improved site responsiveness; fixed dark mode flicker
• Marie Kondo-ed unused files & dead code
18.05.2025 21:06
👍 5
🔁 1
💬 1
📌 0
In orgs pushing the envelope, there's always a minority that can be counted on to get shit done against all odds, driven by force of will, resourcefulness, influence, etc. When you identify them, vest in them authority, autonomy, and step back and watch them perform miracles.
14.05.2025 05:22
👍 5
🔁 0
💬 1
📌 0

bsky share button
opps! thanks for letting me know, fixed!
07.05.2025 02:57
👍 3
🔁 0
💬 0
📌 0

AI Engineer World's Fair 2025
The AI Engineer World's Fair is the biggest technical AI event of the year, happening Summer 2025, the one place you can meet with ~every major AI lab from OpenAI to Anthropic to Cohere, every AI infr...
p.s., If you’re interested in topics like this, my friends Ben and Swyx are organizing the AI Engineer World’s Fair in San Francisco on 3rd - 5th June. Come talk to builders deploying AI systems in production. Here’s a big discount for tickets: ti.to/software-3/a...
07.05.2025 00:25
👍 1
🔁 0
💬 0
📌 0
Here's a three-minute demo of news-agents in action. It's pretty cool at the 30-second mark how the sub-agents get spawned! We then see the main agent assigning tasks and polling for progress, and finally shutting the sub-agents down when they're done with their assigned tasks.
07.05.2025 00:24
👍 3
🔁 0
💬 1
📌 0
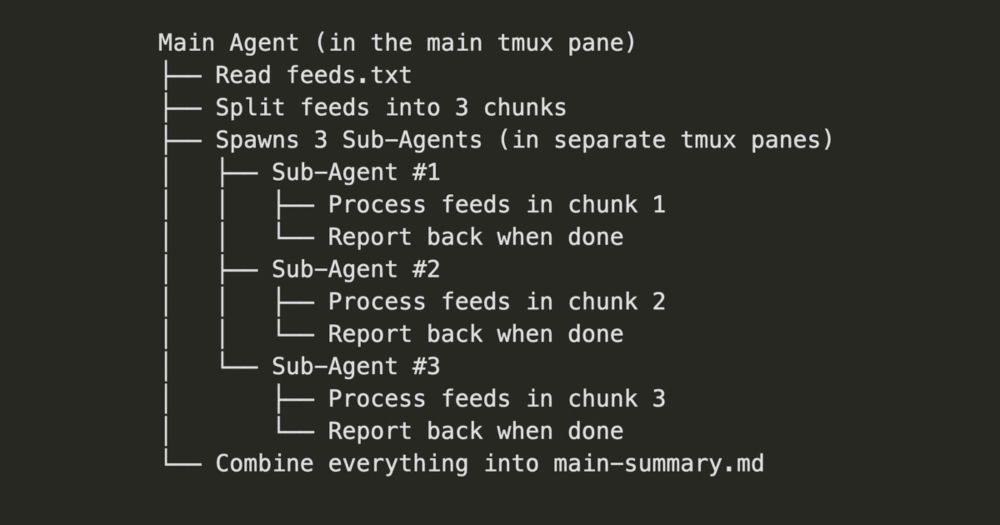
Building News Agents for Daily News Recaps with MCP, Q, and tmux
Learning to automate simple agentic workflows with Amazon Q CLI, Anthropic MCP, and tmux.
To better understand MCPs and agentic workflows, I built news-agents to generate a daily news recap. The main agent spawns sub-agents, assigning them news feeds to parse and summarize, and then generates a final overall summary plus analysis.
eugeneyan.com/writing/news...
07.05.2025 00:21
👍 22
🔁 4
💬 4
📌 0

Effective Evals for AI products
@hamel.bsky.social & @sh-reya.bsky.social are two of the world's best on evals. They've built evals for 35+ AI apps & helped teams ship confidently. Now they'll teach everything they know on building evals that work.
Enrollment closes in 4 days.
Secret 35% discount code: maven.com/parlance-lab...
30.04.2025 02:56
👍 4
🔁 2
💬 0
📌 0

The Art of Doing Science and Engineering: Learning to Learn by Richard Hamming
The Art of Doing Science and Engineering: Learning to Learn by Richard Hamming only $1.99 for the Kindle version today: amazon.com/dp/B088TMLQDC
27.04.2025 23:01
👍 8
🔁 0
💬 0
📌 0

An LLM‑as‑Judge Won't Save The Product—Fixing Your Process Will
Applying the scientific method, building via eval-driven development, and monitoring AI output.
Enjoyed this on eval-driven product development from @eugeneyan.com. It chimes with my own experiences building around LLMs and search engines, including the thoughts on automated evaluators.
When deconstructed, EDD is just the good old scientific method under a new name
26.04.2025 18:28
👍 7
🔁 2
💬 0
📌 0
Surround yourself with people whose "work" is their calling, craft, and play.
They are intrinsically motivated, are driven to excel and do what's right, and and get so much shit done just because it's fun.
26.04.2025 18:01
👍 13
🔁 0
💬 0
📌 0
Some of the anti-AI stuff feels a bit like when people would say "don't use Wikipedia as a source." It's just like anything else, a piece of information that you weigh against multiple sources and your own understanding of its likely failure modes
26.04.2025 13:23
👍 454
🔁 38
💬 563
📌 437
because you’ll keep discovering new ground truth that previous ground truth didn’t cover. in conventional ML, you’d get a ton of ground truth, typically your entire traffic (e.g., search, fraud, forecast errors). now, unless you design your product with implicit feedback, you need to label data
23.04.2025 14:29
👍 1
🔁 0
💬 0
📌 0
yeap, some human oversight still needed for now
23.04.2025 03:27
👍 0
🔁 0
💬 1
📌 0

An LLM‑as‑Judge Won't Save Your Product—Fixing Your Process Will
Applying the scientific method, building via eval-driven development, and monitoring AI output.
Product evals are misunderstood. Many teams think that adding another tool, metric, or llm-as-judge will solve all their problems and save their product. But that just dodges the hard truth and avoids the real work. Here's how to fix your process instead.
eugeneyan.com/writing/eval...
23.04.2025 02:45
👍 20
🔁 2
💬 1
📌 0
did you define what rlvr was in the writeup?
19.04.2025 18:25
👍 1
🔁 0
💬 1
📌 0
The default state of projects is to drift toward entropy; you need to actively resist & reverse it.
19.04.2025 00:19
👍 11
🔁 1
💬 1
📌 0




