Some personal news: I've joined sophont.med to help build the next generation of open medical foundation models.
We've relaunched medarc.ai, our open science research community. Join us if you want to help advance open medical AI.
And we are hiring.
27.10.2025 19:08
👍 2
🔁 1
💬 1
📌 0
counterpoint: GPT-5 does this, it says it doesn’t know rather than hallucinate, the world hasn’t fallen apart
13.09.2025 11:50
👍 20
🔁 4
💬 3
📌 0

ModernBERT goes MULTILINGUAL!
One of the most requested models I've seen, @jhuclsp.bsky.social has trained state-of-the-art massively multilingual encoders using the ModernBERT architecture: mmBERT.
Stronger than an existing models at their sizes, while also much faster!
Details in 🧵
09.09.2025 14:54
👍 14
🔁 6
💬 1
📌 0
ChatGPT has been the best technical search engine since o4-mini.
Thinking Mini still makes for a good faster search if you don’t need the extra reasoning ability.
06.09.2025 22:19
👍 0
🔁 0
💬 0
📌 0
GPT 5 Thinking (the smartest one) ignored the low quality sources and only cited the high quality and reliable sources.
24.08.2025 21:53
👍 0
🔁 0
💬 0
📌 0
A modern example: When attempting to trick GPT 5 + search with a question on the health benefits of raw milk, GPT 5 Fast (the less smart one) started out by citing the raw milk institute before eventually concluding there aren’t any benefits and citing high quality sources.
24.08.2025 21:53
👍 0
🔁 0
💬 1
📌 0
Good LLMs do know and/or can reason about these things. Small, cheap, and often free LLMs are the models which cannot.
Remember the glue on pizza Reddit post that the subpar Google AI cited uncritically? Bing’s then integration of GPT 3.5 recognized the Reddit post as sarcasm.
24.08.2025 21:53
👍 0
🔁 0
💬 1
📌 0
Writing Speed-of-Light Flash Attention for 5090 in CUDA C++ by Thien Tran
He walkthrough how he learned to implement Flash Attention for 5090 in CUDA C++. The main objective is to learn writing attention in CUDA C++,
24.08.2025 00:45
👍 13
🔁 3
💬 1
📌 0
Microsoft made a useful LLM copilot tool that could summarize text in spreadsheets. They provided clear instructions about how to use it and not to use it. In response, journalists are now mocking them for doing exactly the right thing and showing how to use and not use the tools.
21.08.2025 01:50
👍 111
🔁 20
💬 12
📌 2
Reports of AI eating entry level jobs are greatly exaggerated.
My guess is current and near-future LLMs are more likely to increase the demand for programmers, not decrease demand (Jevons Paradox).
18.07.2025 17:06
👍 1
🔁 0
💬 1
📌 0
There isn't a canonical version, but there are retrieval models from GTE and Nomic which might work for your task.
GTE: huggingface.co/Alibaba-NLP/...
Nomic: huggingface.co/nomic-ai/mod...
20.02.2025 16:35
👍 1
🔁 0
💬 0
📌 0
For more details, including our simple training method, see Benjamin Clavié's twitter announcement, our model, blog post, and paper.
Twitter: x.com/bclavie/stat...
Model: huggingface.co/answerdotai/...
Blog: www.answer.ai/posts/2025-0...
Paper: arxiv.org/abs/2502.03793
10.02.2025 18:13
👍 1
🔁 0
💬 0
📌 0

Can all encoders be instruction-tuned? Can we replicate ModernBERT's results with an older model like RoBERTa or peer model like GTE-en-MLM?
No. And it's not close.
10.02.2025 18:13
👍 2
🔁 0
💬 2
📌 0

When we finetune ModernBERT-Large-Instruct on task specific datasets, the generative MLM head is better or nearly equal to standard classification heads.
10.02.2025 18:13
👍 0
🔁 0
💬 1
📌 0
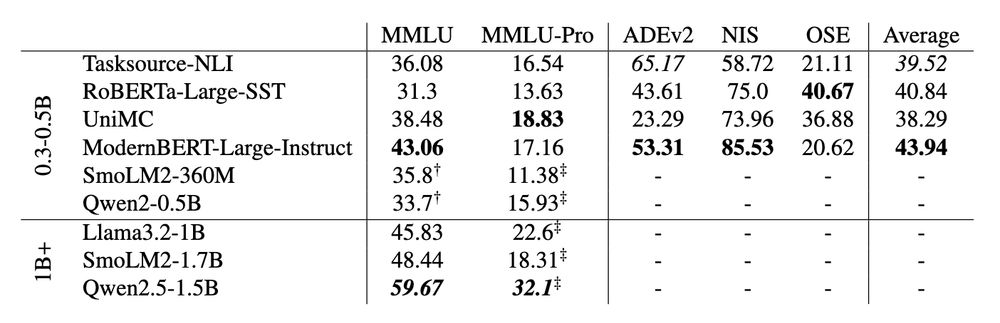
After instruction tuning on Flan, ModernBERT-Large-Instruct outperforms similarly sized LLMs on MMLU & MMLU-Pro, and achieves ~90 percent of Llama 3.2 1B's performance with ~65 percent fewer parameters.
10.02.2025 18:13
👍 1
🔁 0
💬 1
📌 0
![from transformers import pipeline
model_name = "answerdotai/ModernBERT-Large-Instruct"
fill_mask = pipeline("fill-mask", model=model_name, tokenizer=model_name)
text = """You will be given a question and options. Select the right answer.
QUESTION: If (G, .) is a group such that (ab)^-1 = a^-1b^-1, for all a, b in G, then G is a/an
CHOICES:
- A: commutative semi group
- B: abelian group
- C: non-abelian group
- D: None of these
ANSWER: [unused0] [MASK]"""
results = fill_mask(text)
answer = results[0]["token_str"].strip()
print(f"Predicted answer: {answer}") # Answer: B](https://cdn.bsky.app/img/feed_thumbnail/plain/did:plc:psfkl7gi24rg5rhvv7z6mly3/bafkreid6ko23ckgz2mwpp7zj3p6n333vmg5c2r5bghon77g4el6322z6oa@jpeg)
from transformers import pipeline
model_name = "answerdotai/ModernBERT-Large-Instruct"
fill_mask = pipeline("fill-mask", model=model_name, tokenizer=model_name)
text = """You will be given a question and options. Select the right answer.
QUESTION: If (G, .) is a group such that (ab)^-1 = a^-1b^-1, for all a, b in G, then G is a/an
CHOICES:
- A: commutative semi group
- B: abelian group
- C: non-abelian group
- D: None of these
ANSWER: [unused0] [MASK]"""
results = fill_mask(text)
answer = results[0]["token_str"].strip()
print(f"Predicted answer: {answer}") # Answer: B
One of the questions we debated while training ModernBERT was whether a modern trained encoder would unlock zero-shot reasoning using only it's generative head?
Spoilers: the answer is yes.
10.02.2025 18:13
👍 28
🔁 6
💬 3
📌 0

The latest open artifacts (#6): Reasoning models, China's lead in open-source, and a growing multimodal space
Artifacts log 6 The open LM ecosystem yet again accelerates.
If you want to quickly catch up on all the open modeling things (DeepSeek, ModernBERT, etc.), this was a great overview, by @natolambert.bsky.social.
I somehow got into an argument last week with someone who was insisting that all models are industrial blackboxes... and I wish I'd had this on hand.
27.01.2025 15:05
👍 49
🔁 10
💬 0
📌 1
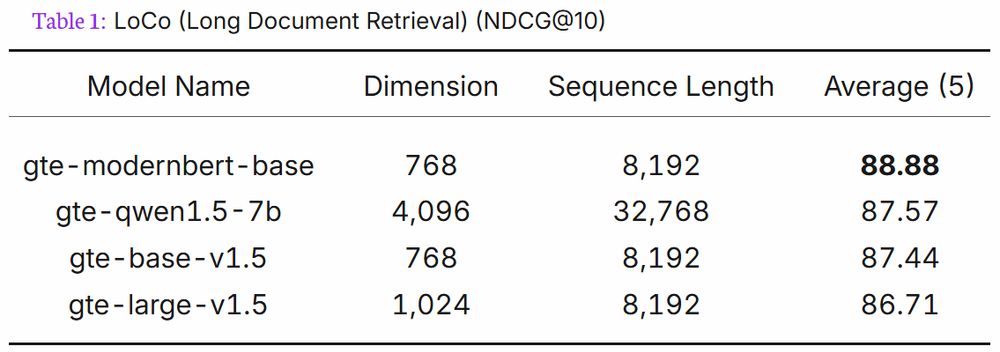
In addition to being the best retrieval model under 300M params on METB (without extra work), and top 10 for under 1B, here's a fun tidbit from Alibaba's GTE ModernBERT model card:
gte-modernbert-base beats gte-qwen1.5-7b on LoCo long context retrieval with 7B less parameters.
23.01.2025 19:22
👍 3
🔁 0
💬 1
📌 0
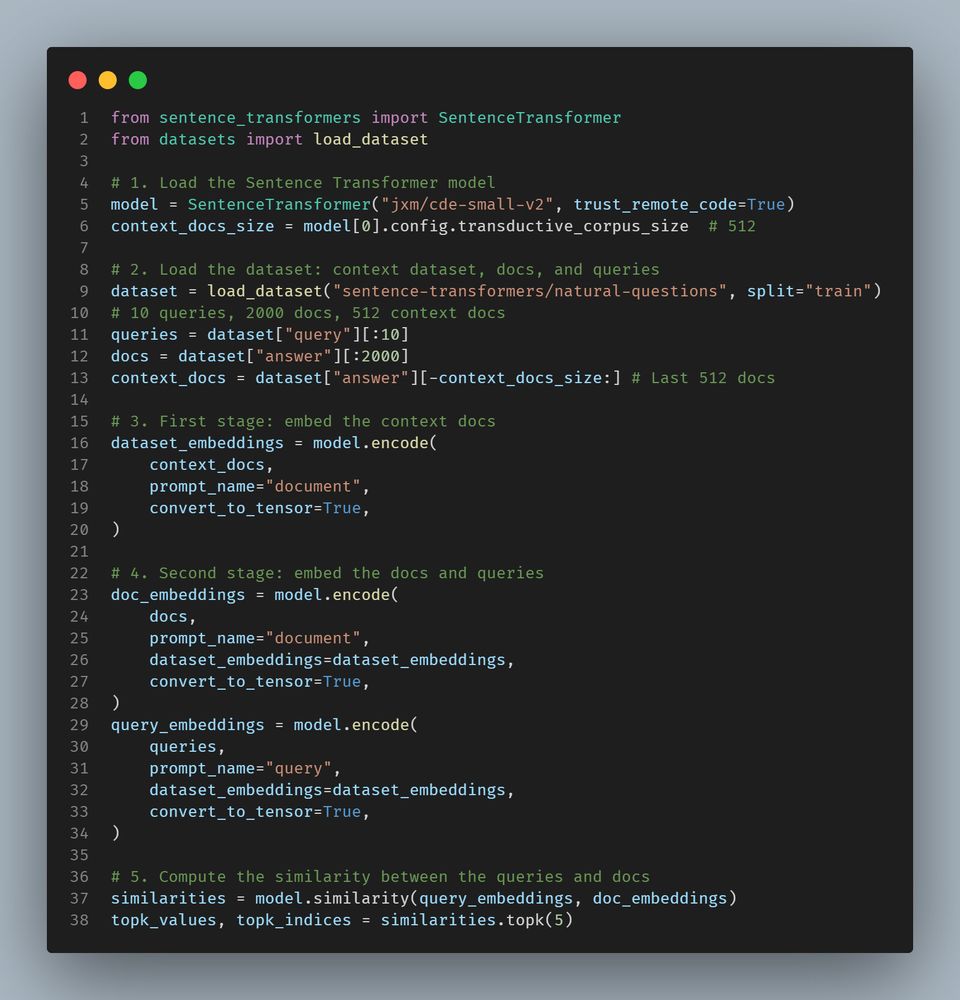
The newest extremely strong embedding model based on ModernBERT-base is out: `cde-small-v2`. Both faster and stronger than its predecessor, this one tops the MTEB leaderboard for its tiny size!
Details in 🧵
14.01.2025 13:21
👍 31
🔁 7
💬 1
📌 1
ModernBERT-embed-base is awesome because it allows to use ModernBERT-base for various tasks out-of-the-box
But the large variant of ModernBERT is also awesome...
So today, @lightonai.bsky.social is releasing ModernBERT-embed-large, the larger and more capable iteration of ModernBERT-embed!
14.01.2025 15:32
👍 12
🔁 2
💬 1
📌 0

Finally, a Replacement for BERT: Introducing ModernBERT
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
What's ModernBERT? It's a drop-in replacement for existing BERT models, but smarter, faster, and supports longer context.
Check out our announcement post for more details: huggingface.co/blog/modernb...
10.01.2025 18:28
👍 2
🔁 0
💬 0
📌 0
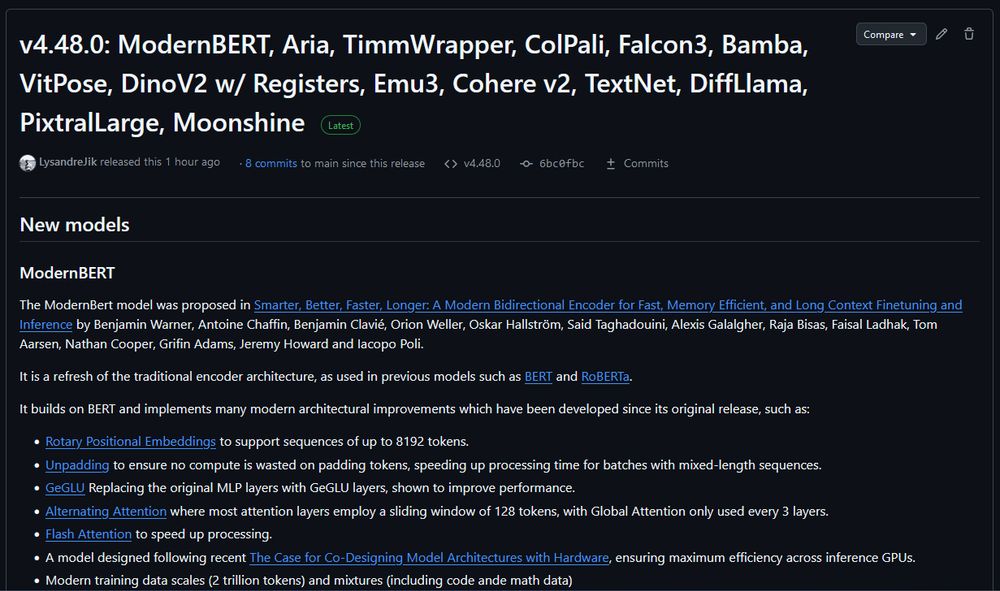
Transformers v4.48.0: ModernBERT, Aria, TimmWrapper, ColPali, Falcon3, Bamba, VitPose, DinoV2 w/ Registers, Emu3, Cohere v2, TextNet, DiffLlama, PixtralLarge, Moonshine
ModernBERT is officially released on Transformers v4.48.0. You no longer need to install from git to use.
If you are plugging ModernBERT into an existing encoder finetuning pipeline, try increasing the learning rate. We've found that ModernBERT tends to prefer a higher LR than older models.
10.01.2025 18:28
👍 11
🔁 3
💬 1
📌 0
*Actually, that’s good compared to the 4090’s PCIe 4 without NVLink
07.01.2025 07:12
👍 0
🔁 0
💬 0
📌 0
The good: 32GB
The bad: $2,000
The Ugly*: PCIe 5 without NVLink
07.01.2025 07:12
👍 0
🔁 0
💬 1
📌 0

Basically, a frontier model like OpenAI’s O1 is like a Ferrari SF-23. It’s an obvious triumph of engineering, designed to win races, and that’s why we talk about it. But it takes a special pit crew just to change the tires and you can’t buy one for yourself. In contrast, a BERT model is like a Honda Civic. It’s also an engineering triumph, but more subtly, since it is engineered to be affordable, fuel-efficient, reliable, and extremely useful. And that’s why they’re absolutely everywhere.
Via @simonwillison.net's excellent blog, I found this great quote about AI models, from @benjaminwarner.dev et al. www.answer.ai/posts/2024-1...
It seems to me that AI will be most relevant in people's lives because the Honda Civic is ubiquitous, not so much because everyone is driving a Ferrari.
01.01.2025 16:04
👍 2
🔁 1
💬 1
📌 0
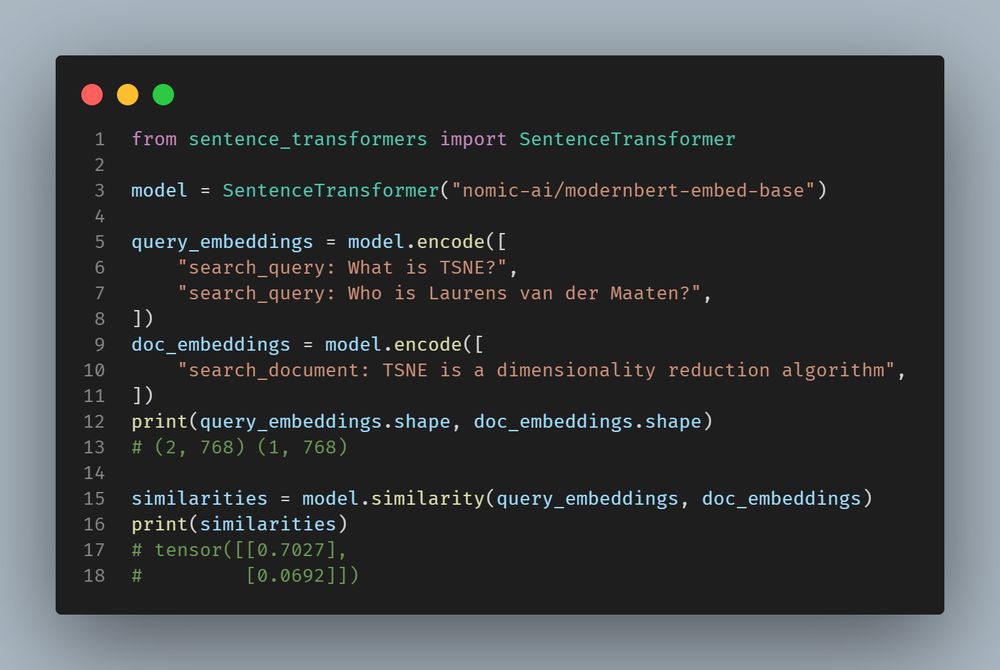
That didn't take long! Nomic AI has finetuned the new ModernBERT-base encoder model into a strong embedding model for search, classification, clustering and more!
Details in 🧵
31.12.2024 15:43
👍 37
🔁 10
💬 2
📌 1
ModernBERT is a “foundation model” so you’ll either need to finetune it for entailment/NLI or wait for someone else to finetune it. I suspect it would be good at NLI once finetuned.
24.12.2024 22:24
👍 3
🔁 0
💬 2
📌 0


