
Gandalf the White. A quote for our times.
14.01.2026 01:24
👍 0
🔁 0
💬 1
📌 0
Gandalf the White. A quote for our times.
The red cups are a brand called solo cups. They have always been red
I’m at @colmweb.org this week in Montreal. Come see our BoundlessBPE paper in the Wed morning poster session. Love to talk to anyone else here, especially about tokenization. #COLM2025
I believe he’s talking about Olin College of Engineering. Created from scratch as an undergraduate only school, with the first class in 2002. Kind of a Harvey Mudd of the east. Campus is near me, and they seem to attract great students.

The other is that is there isn't a way to specify an initial vocabulary with all 256 bytes including the continuation character ##. See github.com/huggingface/.... So in short, if you use their WordPiece you might get <UNK> tokens.
There are two different ways that the Huggingface Word Piece implementation can produce <UNK> tokens even with ByteLevel pretokenization. A nice blog post from Stéphan Tulkens talks about how to fix one of them, in response to a question of mine.
stephantul.github.io/blog/better-...
I've been using GPT-5 on my phone (since it isn't my web account yet). I've had several bad responses with logical inconsistencies. My hot take: what if GPT-5 is mostly about saving OpenAI money on inference, which is why they are deprecating all the other models so quickly.
@crampell.bsky.social’s post got me to thinking and…yes…Trump has apparently canceled the research grant of Judea Pearl, who is one of the world’s leading scholars, is Jewish, Israeli-American, & is vocally opposed to antisemitism, & is the father of Daniel Pearl.
www.science.org/content/arti...
Interested in multilingual tokenization in #NLP? Lisa Beinborn and I are hiring!
PhD candidate position in Göttingen, Germany: www.uni-goettingen.de/de/644546.ht...
PostDoc position in Leuven, Belgium:
www.kuleuven.be/personeel/jo...
Deadline 6th of June
I've posted a few papers I missed including yours here bsky.app/profile/crai.... Thomas pointed that out about 5 seconds after I posted on the discord :-)

16) Causal Estimation of Tokenisation Bias
Pietro Lesci et al
aclanthology.org/2025.acl-lon...

15) Tokenisation is NP-Complete
Philip Whittington et al
aclanthology.org/2025.acl-lon...

14) GRaMPa: Subword Regularisation by Skewing Uniform Segmentation Distributions with an Efficient Path-counting Markov Model
Thomas Bauwens et al
aclanthology.org/2025.acl-lon...
And of course I missed some tokenization related papers at #ACL2025 in my previous post. Any more I should add?

13) Evaluating Tokenizer Adaptation Methods for Large Language Models on Low-Resource Programming Languages
Georgii Andriushchenko et al
aclanthology.org/2025.acl-srw...

12) Retrofitting Large Language Models with Dynamic Tokenization
Darius Feher et al
aclanthology.org/2025.acl-lon...

11) TokAlign: Efficient Vocabulary Adaptation via Token Alignment
Chong Li et al
aclanthology.org/2025.acl-lon...

10) Sticking to the Mean: Detecting Sticky Tokens in Text Embedding Models
Kexin Chen et al
aclanthology.org/2025.acl-lon...

9) Inconsistent Tokenizations Cause Language Models to be Perplexed by Japanese Grammar
Andrew Gambardella et al
aclanthology.org/2025.acl-sho...

8) Adversarial Tokenization
Renato Lui Geh et al
aclanthology.org/2025.acl-lon...

7) Incorporating Domain Knowledge into Materials Tokenization
Yerim Oh et al
aclanthology.org/2025.acl-lon...

6) Beyond Text Compression: Evaluating Tokenizers Across Scales
Jonas F. Lotz et al
aclanthology.org/2025.acl-lon...

5) Enhancing Character-Level Understanding in LLMs through Token Internal Structure Learning
Zhu Xu et al
aclanthology.org/2025.acl-lon...

4) Unsupervised Morphological Tree Tokenizer
Xiang Hu et al
aclanthology.org/2025.finding...

3) Splintering Nonconcatenative Languages for Better Tokenization
Yuval Pinter et al
aclanthology.org/2025.finding...

2) Tokenization is Sensitive to Language Variation
Anna Wegmann et al
aclanthology.org/2025.finding...
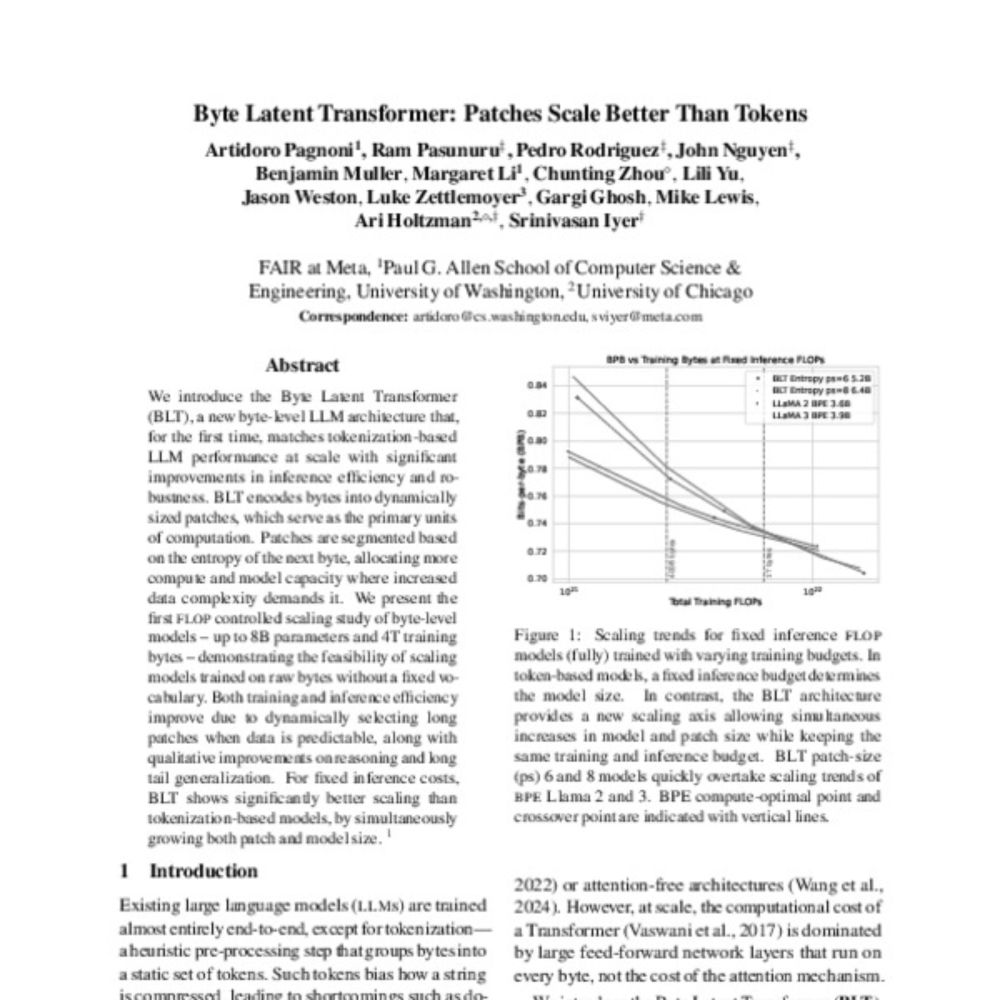
1) Byte Latent Transformer: Patches Scale Better Than Tokens
Artidoro Pagnoni et al
aclanthology.org/2025.acl-lon...
I'm sadly not at #ACL2025, but the work on tokenization seem to continue to explode. Here are the tokenization related papers I could find, in no particular order. Let me know if I missed any.
Really grateful to the organizers for the recognition of our work!
You’re right these results apply to general “big” datasets like ThePile or RedPajama. There are several papers at ICML on weighting datasets like Chameleon (icml.cc/virtual/2025...) that could probably let you get away with less data.