

Lots more in our paper (arxiv.org/abs/2502.12197) and code (github.com/normster/Rea...)
19.02.2025 06:06
👍 0
🔁 0
💬 0
📌 0
Lots more in our paper (arxiv.org/abs/2502.12197) and code (github.com/normster/Rea...)
Reasoning (o3-mini and R1) seems highly effective for more retrieval-bottlenecked prompts (i.e. forgetting relevant guardrails), less so for adversarial inputs/prompt injections. Definitely an exciting direction to explore further.

Standard training techniques like good data curation, SFT -> DPO, work reasonably well, and the pass/fail nature of guardrail adherence enables the use of tricks like classifier-free guidance/contrastive decoding to further improve performance

RealGuardrails is our new dataset to 1) evaluate system prompt robustness on realistic prompts scraped from the ChatGPT store, and 2) evaluate methods for improving open weight models like Llama 3
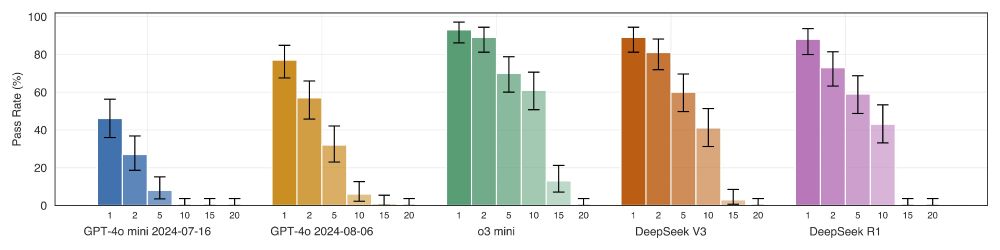
System prompts are a critical control plane for LLMs/AI agents, but models vary widely in their robustness. We found a "complexity wall" at ~10 guardrails where prompt adherence declines rapidly even on totally benign inputs
I learned about how legal journals work earlier this year and have wondered if it could work for ML/AI: reviewing becomes a way for students to distinguish themselves rather than a chore
mindboggling that bytedance is 1) suing the author for damages and sabotage and 2) keeping their name on the paper/award without retracting it
absolutely wild allegations being shared about the author of the NeurIPS 2024 best paper winner: var-integrity-report.github.io.
really feels like the bottom is dropping out from academic ML research with the amount of brazen dishonesty

Going off FLOP/s and power, looks like these are very roughly 3/4 of an H100?

"AWS is currently deploying a cluster with 200k+ Trainium2 chips for Anthropic called “Project Rainer”" semianalysis.com/2024/12/03/a...

top loss curves do look sketchy but idk how bad this is for an RL task. bottom curves don't obviously asymptote but they also shouldn't with learning rate decay (which the open source release seems to use? github.com/google-resea...)

my takeaway from Vighnesh's writeup: google's main argument about under-training/lack of pre-training isn't super convincing. convergence of train loss is not always desirable. early stopping can help, and their own paper shows mixed results on importance of pre-training
i've been confusedly semi-following the RL chip design/AlphaChip story for a few years trying to understand what the core disagreement was, and finally found a summary that (seems) to collate and explain all the relevant artifacts
I’d like to join!