
Really great collaborating with @nathanlile.bsky.social!
Reach out if you're working on synthetic data generation, offline RL, or simulating agentic behavior.
16.07.2025 18:44
👍 1
🔁 0
💬 0
📌 0
Really great collaborating with @nathanlile.bsky.social!
Reach out if you're working on synthetic data generation, offline RL, or simulating agentic behavior.
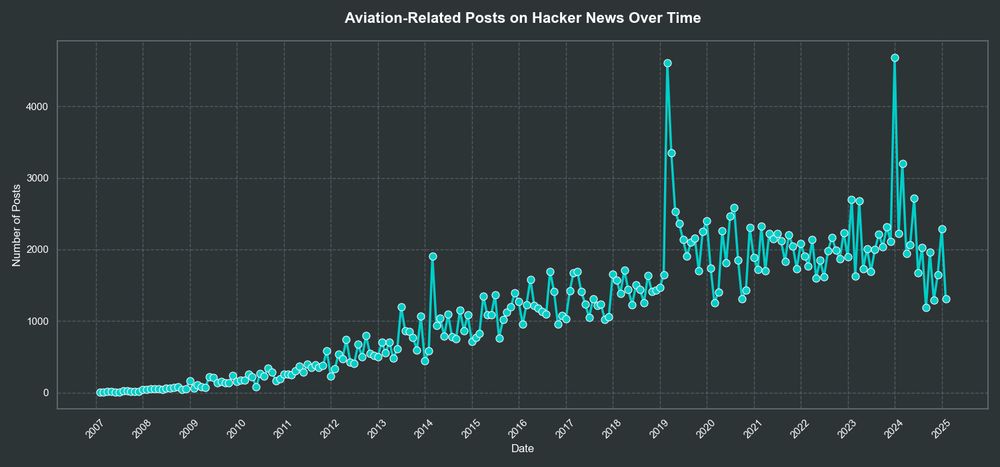

Had a lot of fun with this one! Turns out that >1.5% of posts on Hacker News are aviation-related in recent years. www.skysight.inc/blog/hacker-...
Gave a fun talk at the @modal-labs.bsky.social and Mistral AI
demo night last week in SF! We discussed open-source model security, applying some of the large-scale inference techniques we've been working on recently.
www.skysight.inc/blog/model-s...
Do they have to nerd snipe us this bad?
show us the way
I've always wanted to like python notebooks

🥵 #dataBS
Thank you @jakthom.bsky.social!
Anyone want to make #graphBS a thing?
Depressing will be the day a developer asks me:
"What is StackOverflow?"
It seems pretty clear to me that this thing will be as big/bigger than X in terms of sheer number of users
Do you think this is different than human confidence? I'd say 99.9% of what we think is true is second-hand knowledge

Somewhat disagree here. Have you ever looked at logprobs? The model far prefers steering in directions that it feels confident in given alternatives. cookbook.openai.com/examples/usi...
So do humans! It's why we have QA/testing, and jobs that are just pure oversight.
You might expect both an LLM and a human to get a handful of data labeling tasks wrong, but have it checked with a verifier/adversarial LLM and you'll likely get ~100% accuracy.
That being said, my guess is progress will resume when we start to generate high-quality, focused synthetic data. Sort of like forcing a human to go to the library and acquire actual knowledge instead of scrolling on social media all day
How can we be surprised that LLM scaling laws don't hold when the training data is literally just crap people write on the internet?
Btw the bait is me just saying there is no debate
Okay now that everyone is here who wants to get baited into an R vs. Python debate?
Seems like the holiday is bringing huge amounts of new users over here. @jaz.bsky.social is your data supporting this?
Who is going to build the billion dollar slop/non-slop classifier?
While a lot of the content on X is clearly written by humans, it's sort of degraded into subhuman patterns of engagement. Lots of cryptic speak, baiting, trolling, inflaming, etc. Glad this place has actual humans posting actual human thoughts.
This is super cool! One has to assume that the most open, programmable, and hackable content platforms win in the long run
Becoming a more confident engineer isn't about writing less dumb code; it's about accepting the fact that everyone else's code is just as dumb as yours
GenAI - pay more for inefficient ML models
Crypto - pay more for others to verify your own transactions
SaaS - pay more for something a spreadsheet can do
Cloud - pay more for someone else’s computer
Mobile - pay more for apps that can run in a browser
I'm a big fan of the "anti" data warehouse approach! Users shouldn't be forced to store their data in a third-party system to get the benefits of its processing capabilities.
People forget that it's not unusual for Apple to release products that initially suck and are iteratively refined. They take big bets.
The original iPhone, Apple Maps, etc.
My guess is Apple Intelligence will have a dominant, frontier consumer AI product within ~5 years.
Startup idea: Cursor, but it just shits on your patterns and bullies you into refactoring your entire codebase every time you ask it a question.
4. The notion of consensus will be a lot more important, and agentic moderators might be in charge of modifying embedding indexes to more accurately represent reality and remove hallucinations/biases
3. APIs and internet-based services might not be as rigid. An LLM can more freely negotiate with a service provider if there request doesn't conform to a certain standard.
